
通信网络/IP 表
netfilter 框架,其中 iptables 是其中的一部分,允许 系统管理员 定义如何处理网络 数据包 的规则。规则被分组到链 中 - 每个链都是规则的有序列表。链被分组到表 中 - 每个表与不同的数据包处理类型相关联。
每个规则包含一个指定哪些数据包与之匹配的规范和一个目标,它指定如果数据包与该规则匹配,则对数据包执行的操作。到达或离开计算机的每个网络数据包至少会遍历一个链,并且该链上的每个规则都会尝试匹配该数据包。如果规则与数据包匹配,则遍历停止,并且该规则的目标 指示对该数据包执行的操作。如果数据包到达预定义链的末尾,但没有被该链上的任何规则匹配,则该链的策略 目标指示对该数据包执行的操作。如果数据包到达用户定义链的末尾,但没有被该链上的任何规则匹配,或者用户定义的链为空,则遍历继续在调用链上进行(隐式目标 RETURN)。只有预定义的链具有策略。
iptables 中的规则被分组到链中。链是一组针对 IP 数据包的规则,用于确定对它们执行的操作。每个规则都可能将数据包从链中丢弃(短路),并且不会考虑其他链。一个链可能包含一个指向另一个链的链接 - 如果数据包通过了整个链或匹配了 RETURN 目标规则,它将继续在第一个链中进行。嵌套链的数量没有限制。存在三个基本链(INPUT、OUTPUT 和 FORWARD),用户可以创建任意数量的链。规则可能只是一个指向链的指针。
存在三个内置表,每个表都包含一些预定义的链。扩展模块可以创建新的表。管理员可以在任何表中创建和删除用户定义的链。最初,所有链都是空的,并且具有一个策略目标,该目标允许所有数据包通过,而不会被阻止或以任何方式更改。
- filter 表 — 该表负责过滤(阻止或允许数据包继续进行)。每个数据包都会通过 filter 表。它包含以下预定义的链,并且任何数据包都会通过其中的一个
- INPUT 链 — 所有注定要发送到此系统的数据包都会通过此链(因此有时被称为LOCAL_INPUT)
- OUTPUT 链 — 此系统创建的所有数据包都会通过此链(又名LOCAL_OUTPUT)
- FORWARD 链 — 所有仅仅经过此系统的数据包(被 路由)都会通过此链。
- nat 表 — 该表负责设置重写数据包地址或端口的规则。任何连接中的第一个数据包都会通过此表:此处的所有判决都会决定如何重写该连接中的所有数据包。它包含以下预定义的链
- mangle 表 — 该表负责调整数据包选项,例如 服务质量。所有数据包都会通过此表。由于它是为高级效果而设计的,因此它包含所有可能的预定义链
- PREROUTING 链 — 所有以任何方式进入系统的数据包,在路由决定是否转发数据包(FORWARD 链)还是将其发送到本地(INPUT 链)之前。
- INPUT 链 — 所有注定要发送到此系统的数据包都会通过此链
- FORWARD 链 — 所有仅仅经过此系统的数据包都会通过此链。
- OUTPUT 链 — 此系统创建的所有数据包都会通过此链
- POSTROUTING 链 — 所有离开系统的数据包都会通过此链。
除了内置链之外,用户可以在每个表中创建任意数量的用户定义链,这使他们能够以逻辑方式对规则进行分组。
每个链包含一个规则列表。当数据包被发送到链时,它会按顺序与链中的每个规则进行比较。该规则指定数据包必须具有哪些属性才能与该规则匹配,例如 端口号 或 IP 地址。如果该规则不匹配,则继续处理下一个规则。但是,如果该规则确实与数据包匹配,则会遵循该规则的目标 指令(并且通常会中止对该链的进一步处理)。某些数据包属性只能在某些链中检查(例如,输出网络接口在 INPUT 链中是无效的)。某些目标只能在某些链中或某些表中使用(例如,SNAT 目标只能在 nat 表的 POSTROUTING 链中使用)。
规则的目标可以是用户定义链的名称或以下内置目标之一ACCEPT, DROP, QUEUE,或RETURN。当目标是用户定义链的名称时,数据包会被转移到该链进行处理(很像 子例程 在 编程语言 中的调用)。如果数据包通过用户定义链,而没有被该链中的任何规则操作,则数据包的处理将从当前链中停止的位置继续。这些链间调用可以嵌套到任意深度。
存在以下内置目标
- ACCEPT
- 此目标导致 netfilter 接受数据包。这意味着什么取决于执行接受的链。例如,在 INPUT 链上被接受的数据包被允许由主机接收,在 OUTPUT 链上被接受的数据包被允许离开主机,在 FORWARD 链上被接受的数据包被允许通过主机路由。
- DROP
- 此目标导致 netfilter 丢弃数据包,而不会进行任何进一步处理。该数据包简单地消失,而不会向发送主机或应用程序提供任何关于它被丢弃的事实。这通常会使发送方看起来像是通信超时,这可能会造成混淆(虽然丢弃不需要的入站数据包通常被认为是一个好的安全策略,因为它不会向潜在的攻击者提供任何关于你的主机存在的迹象)。
- QUEUE
- 此目标会导致数据包被发送到 用户空间 中的队列。应用程序可以使用 libipq 库,该库也是 netfilter/iptables 项目的一部分,来修改数据包。如果没有应用程序读取队列,则此目标等同于 DROP。
- RETURN
- 根据官方的 netfilter 文档,此目标具有与从链的末尾掉落相同的效果:对于内置链中的规则,会执行该链的策略。对于用户定义链中的规则,遍历将继续在先前的链中进行,就在跳转到该链的规则之后。
有许多扩展目标可用。以下是一些最常见的目标
- REJECT
- 此目标与“DROP”的效果相同,但会向原始发送者发送错误数据包。它主要用于过滤表中的 INPUT 或 FORWARD 链。数据包类型可以通过“--reject-with”参数控制。拒绝数据包可以明确指出连接已被过滤(ICMP 连接-管理-过滤数据包),尽管大多数用户更喜欢数据包简单地表明计算机不接受该类型的连接(此类数据包将是拒绝 TCP 连接的 tcp-reset 数据包,拒绝 udp 会话的 icmp-port-unreachable 或非 tcp 非 udp 数据包的 icmp-protocol-unreachable)。如果未指定“--reject-with”参数,则默认拒绝数据包始终为 icmp-port-unreachable。
- LOG
- 此目标记录数据包。这可以在任何表中的任何链中使用,并且通常用于调试(例如,查看哪些数据包被丢弃)。
- ULOG
- 此目标记录数据包,但与 LOG 目标不同。LOG 目标将信息发送到 内核 日志,而 ULOG 组播 与此规则匹配的数据包通过 netlink 套接字,以便用户空间程序可以通过连接到套接字来接收这些数据包。
- DNAT
- 此目标导致数据包的目标地址(以及可选的端口)被重写以进行 网络地址转换。必须提供“--to-destination”标志以指示要使用的目标。这仅在 nat 表中的 OUTPUT 和 PREROUTING 链中有效。此决定将被记住,适用于属于同一连接的所有未来数据包,并且回复将将其源地址和端口更改回原始地址(即此数据包的反向操作)。
- SNAT
- 此目标导致数据包的源地址(以及可选的端口)被重写以进行 网络地址转换。必须提供“--to-source”标志以指示要使用的源。这仅在 nat 表中的 POSTROUTING 链中有效,并且与 DNAT 一样,会记住属于同一连接的所有其他数据包。
- MASQUERADE
- 这是一种特殊的,受限的 SNAT 形式,用于动态 IP 地址,例如大多数 互联网服务提供商 为 调制解调器 或 DSL 提供。与其每次 IP 地址更改时都更改 SNAT 规则,不如通过查看数据包匹配此规则时传出接口的 IP 地址来计算要使用的源 IP 地址。此外,它会记住哪些连接使用 MASQUERADE,如果接口地址更改(例如重新连接到 ISP),则所有 NAT 到旧地址的连接都会被遗忘。
- REDIRECT
- REDIRECT 目标用于将数据包和流重定向到机器本身。这意味着,例如,我们可以将所有指向 HTTP 端口的数据包重定向到我们主机上的 HTTP 代理,例如 squid。本地生成的数据包映射到 127.0.0.1 地址。换句话说,这会将目标地址重写到我们自己的主机,用于转发或类似的数据包。当我们想要透明代理时,REDIRECT 目标非常有用,例如,局域网主机根本不知道代理。
- 请注意,REDIRECT 目标仅在 nat 表中的 PREROUTING 和 OUTPUT 链中有效。它在仅从这些链调用,而不在其他地方调用的用户定义链中也有效。REDIRECT 目标只接受一个选项,如下所述。
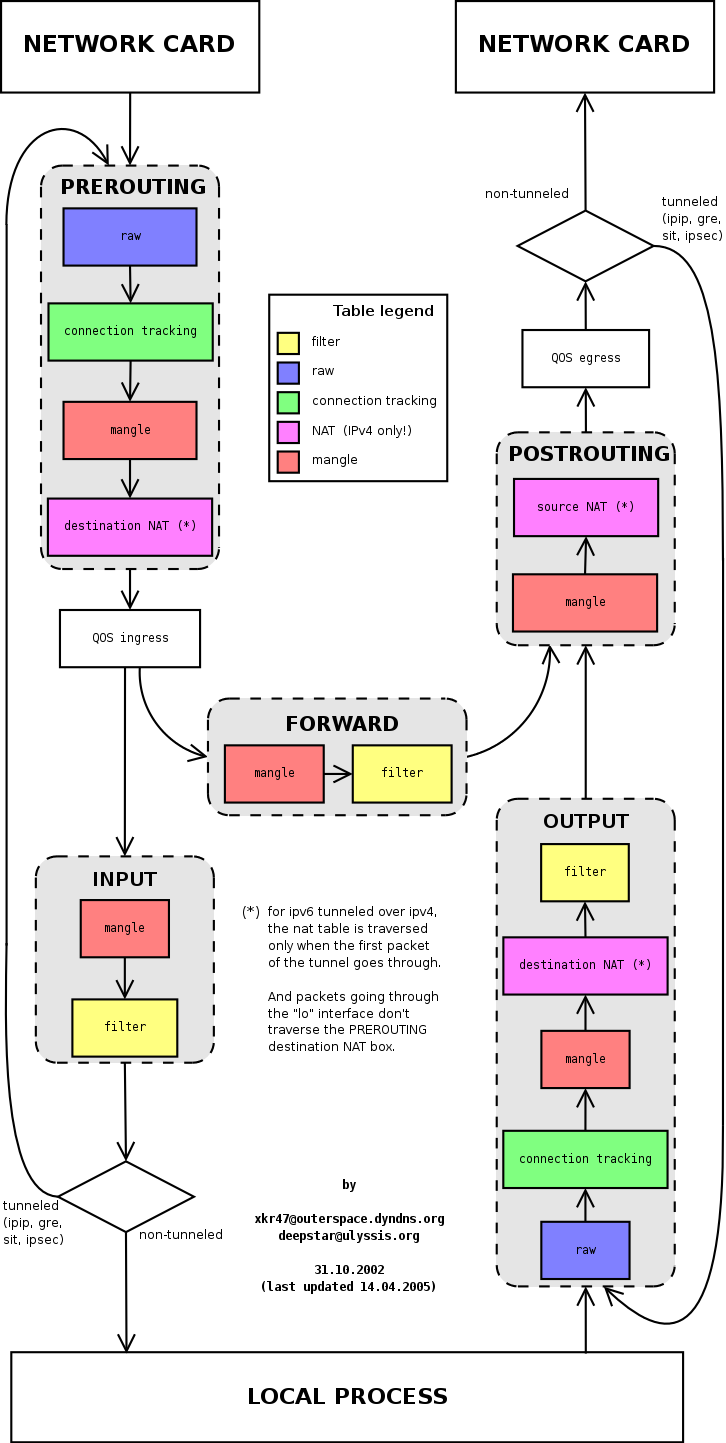
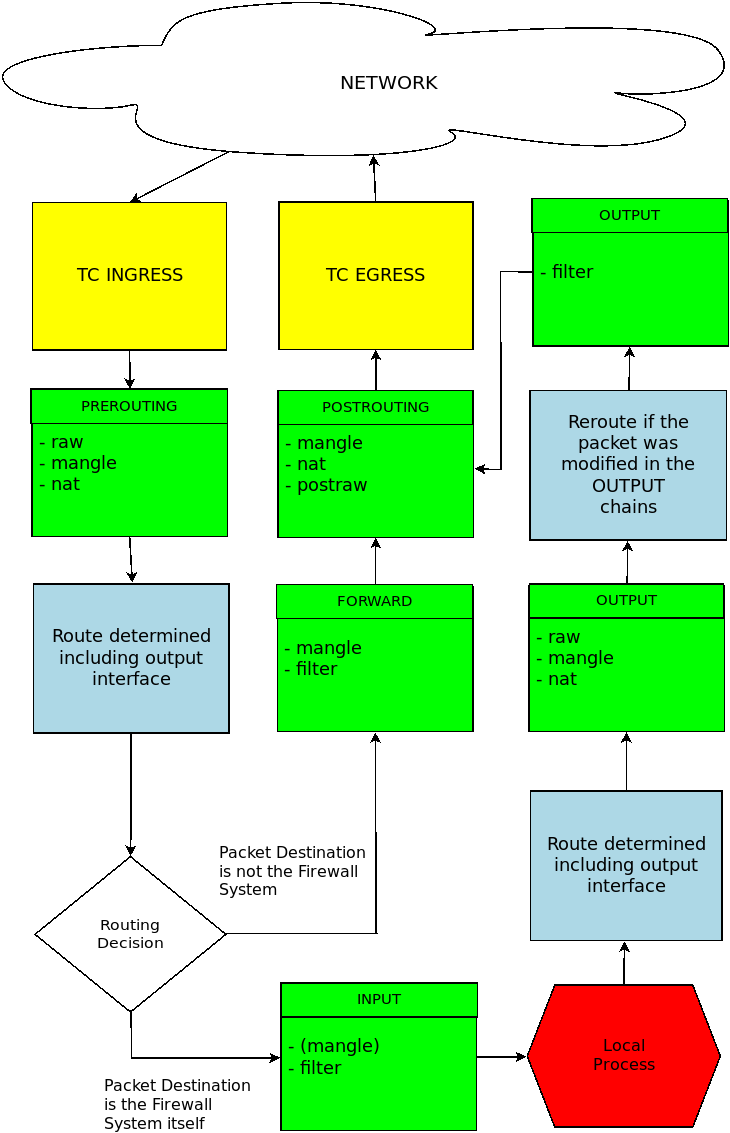
图表
[edit | edit source]这些图表说明了数据包如何遍历内核 netfilter 表/链。

以下资源也可能有用
- http://xkr47.outerspace.dyndns.org/netfilter/packet_flow/packet_flow9.png
- http://www.shorewall.net/images/Netfilter.png
- http://dmiessler.com/images/DM_NF.PNG
- http://linux-ip.net/nf/nfk-traversal.pdf
{kind=link}
{kind=link}
{kind=link}
连接跟踪
[edit | edit source]建立在 netfilter 框架之上的重要功能之一是连接跟踪。连接跟踪允许内核跟踪所有逻辑网络连接或会话,从而关联构成该连接的所有数据包。NAT 依赖于此信息以相同的方式转换所有相关数据包,iptables 可以使用此信息充当状态防火墙。
连接跟踪将每个数据包归类为以下四种状态之一。NEW(尝试建立新的连接),ESTABLISHED(已存在连接的一部分),RELATED(与现有连接相关,但并非实际的现有连接的一部分)或INVALID(不是现有连接的一部分,并且无法建立新的连接)。一个正常的例子是防火墙看到的第一数据包将被归类为NEW,回复将被归类为ESTABLISHED,而 ICMP 错误将是RELATED。与任何已知连接不匹配的 ICMP 错误数据包将是INVALID.
连接状态完全独立于任何TCP 状态。如果主机使用 SYN ACK 数据包响应以确认传入的新 TCP 连接,则 TCP 连接本身尚未建立,但跟踪的连接已建立 - 此数据包将与状态 ESTABLISHED 匹配。
无状态协议(如 UDP)的跟踪连接仍然具有连接状态。
此外,通过使用插件模块,连接跟踪可以了解应用程序层协议,从而理解两个或多个不同的连接是“相关的”。例如,考虑 FTP 协议。建立了控制连接,但无论何时传输数据,都会建立一个单独的连接来传输数据。当加载 ip_conntrack_ftp 模块时,FTP 数据连接的第一数据包将被归类为RELATED而不是NEW,因为它在逻辑上是现有连接的一部分。
iptables 可以使用连接跟踪信息来使数据包过滤规则更强大,更易于管理。“conntrack”匹配扩展允许 iptables 规则检查数据包的连接跟踪分类。例如,一条规则可能只允许NEW来自防火墙内部的数据包到防火墙外部,但允许RELATED和ESTABLISHED在任一方向。这允许来自外部的正常回复数据包(ESTABLISHED),但不允许从外部到内部建立新的连接。但是,如果 FTP 数据连接需要从防火墙外部到防火墙内部,它将被允许,因为数据包将被正确地归类为RELATED到 FTP 控制连接,而不是NEW连接。
iptables
[edit | edit source]iptables 是一个 用户空间 应用程序,它允许系统管理员配置 netfilter 表、链和规则(如上所述)。由于 iptables 需要提升的权限才能操作,因此必须由用户 root 执行,否则它将无法正常工作。在大多数 Linux 系统上,iptables 安装为/sbin/iptables。的详细语法iptables命令在它的 手册页 中有记录,可以通过键入命令“"来显示man iptables".
常用选项
[edit | edit source]在下面显示的每个 iptables 调用形式中,以下常用选项都可用
- -t table
- 使命令应用于指定的table。省略此选项时,命令默认应用于filter 表。
- -v
- 产生详细输出。
- -n
- 产生数字输出(即端口号而不是服务名称,IP 地址而不是 域名)。
- --line-numbers
- 列出规则时,在每条规则的开头添加行号,对应于该规则在其链中的位置。
规则规范
[edit | edit source]大多数 iptables 命令形式要求您提供一个规则规范,该规范用于匹配由链处理的网络数据包流量的特定子集。规则规范还包括一个目标,该目标指定对与规则匹配的数据包执行的操作。以下选项用于(经常组合在一起)创建规则规范。
- -j target
- --jump target
- 指定规则的目标。目标是用户定义链的名称(使用-N选项创建),内置目标之一,ACCEPT, DROP, QUEUE,或RETURN,或扩展目标,例如REJECT, LOG, DNAT,或SNAT。如果规则中省略此选项,则匹配规则将不会影响数据包的命运,但规则上的计数器将递增。
- -i [!] 入接口
- --in-interface [!] 入接口
- 数据包将要接收的接口名称(仅适用于进入 INPUT、FORWARD 和 PREROUTING 链的数据包)。当在接口名称之前使用 '!' 参数时,其意义将被反转。如果接口名称以 '+' 结尾,则以该名称开头的任何接口都将匹配。如果省略此选项,则任何接口名称都将匹配。
- -o [!] 出接口
- --out-interface [!] 出接口
- 数据包将要发送的接口名称(适用于进入 FORWARD、OUTPUT 和 POSTROUTING 链的数据包)。当在接口名称之前使用 '!' 参数时,其意义将被反转。如果接口名称以 '+' 结尾,则以该名称开头的任何接口都将匹配。如果省略此选项,则任何接口名称都将匹配。
- -p [!] 协议
- --protocol [!] 协议
- 匹配指定协议名称的数据包。如果 '!' 位于协议名称之前,则匹配所有不是指定协议的数据包。有效的协议名称是icmp, udp, tcp... 所有有效协议的列表可以在 /etc/protocols 文件中找到。
- -s [!] 源[/前缀]
- --source [!] 源[/前缀]
- 匹配来自指定源地址的 IP 数据包。源地址可以是 IP 地址、带有关联的 w:网络前缀 的 IP 地址或主机名。如果 '!' 位于源之前,则匹配所有不是来自指定源的数据包。
- -d [!] 目标[/前缀]
- --destination [!] 目标[/前缀]
- 匹配要发送到指定目标地址的 IP 数据包。目标地址可以是 IP 地址、带有关联的 w:网络前缀 的 IP 地址或主机名。如果 '!' 位于目标之前,则匹配所有不是要发送到指定目标的数据包。
- --destination-port [!] [端口[:端口]]
- --dport [!] [端口[:端口]]
- 匹配 TCP 或 UDP 数据包(取决于对-p选项的参数),这些数据包的目标是指定的端口或端口范围(当使用端口:端口形式时)。如果 '!' 位于端口规范之前,则匹配所有不是目标为指定端口或端口范围的 TCP 或 UDP 数据包。
- --source-port [!] [端口[:端口]]
- --sport [!] [端口[:端口]]
- 匹配 TCP 或 UDP 数据包(取决于对-p选项的参数),来自指定的端口或端口范围(当使用端口:端口形式时)。如果 '!' 位于端口规范之前,则匹配所有不是来自指定端口或端口范围的 TCP 或 UDP 数据包。
- --tcp-flags [!] 掩码 比较
- 匹配具有某些 TCP 协议标志设置或未设置的 TCP 数据包。第一个参数指定要检查的每个 TCP 数据包中的标志,写为逗号分隔的列表(不允许空格)。第二个参数是一个逗号分隔的标志列表,这些标志必须在那些被检查的标志中设置。标志是:SYN、ACK、FIN、RST、URG、PSH、ALL 和 NONE。因此,选项 "--tcp-flags SYN,ACK,FIN,RST SYN" 将仅匹配设置了 SYN 标志且未设置 ACK、FIN 和 RST 标志的数据包。
- [!] --syn
- 匹配设置了 SYN 标志且未设置 ACK、RST 和 FIN 标志的 TCP 数据包。此类数据包用于启动 TCP 连接。阻止 INPUT 链上的此类数据包将阻止传入的 TCP 连接,但传出的 TCP 连接不受影响。此选项可以与其他选项结合使用,例如--source仅阻止或允许来自某些主机或网络的入站 TCP 连接。此选项等效于 "--tcp-flags SYN,RST,ACK SYN"。如果 '!' 标志位于--syn之前,则选项的意义将被反转。
- 此部分正在建设中。
调用
[edit | edit source]iptables { -A | --append | -D | --delete } chain rule-specification [ options ]
此形式的命令添加(-A或--append)或删除(-D或--delete)指定链中的规则。例如,要向 filter 表(当未指定选项-t时,默认表)的 INPUT 链添加一个规则,以丢弃所有 UDP 数据包,请使用以下命令
- iptables -A INPUT -p udp -j DROP
要删除上述命令添加的规则,请使用以下命令
- iptables -D INPUT -p udp -j DROP
上面的命令实际上删除了 INPUT 链上第一个与规则规范匹配的规则 "-p udp -j DROP"。如果链上有多个相同的规则,则只会删除第一个匹配的规则。
iptables { -R | --replace | -I | --insert } chain rulenum rule-specification [ options ]
此形式的命令替换(-R或--replace)现有规则或插入(-I或--insert)指定链中的新规则。例如,要将 INPUT 链中的第四个规则替换为丢弃所有 ICMP 数据包的规则,请使用以下命令
- iptables -R INPUT 4 -p icmp -j DROP
要将一个新规则插入 OUTPUT 链的第二个槽中,该规则会丢弃所有发送到任何主机上的端口 80 的 TCP 流量,请使用以下命令
- iptables -A INPUT-p tcp -m tcp --dport 22 -j ACCEPT
iptables { -D | --delete } chain rulenum [ options ]
此形式的命令删除指定链中指定数字索引处的规则。规则从 1 开始编号。例如,要从 FORWARD 链删除第三个规则,请使用以下命令
- iptables -D FORWARD 3
iptables { -L | --list | -F | --flush | -Z | --zero } [ chain ] [ options ]
此形式的命令用于列出链中的规则(-L或--list),刷新(即,删除)链中的所有规则(-F或--flush),或将链的字节和数据包计数器归零(-Z或--zero)。如果没有指定链,则操作将对所有链执行。例如,要列出 OUTPUT 链中的规则,请使用以下命令
- iptables -L OUTPUT
要刷新所有链,请使用以下命令
- iptables -F
要将 nat 表中 PREROUTING 链的字节和数据包计数器归零,请使用以下命令
- iptables -t nat -Z PREROUTING
iptables { -N | --new-chain } chain
iptables { -X | --delete-chain } [ chain ]
此形式的命令用于创建(-N或--new-chain)一个新的用户定义链或删除(-X或--delete-chain)一个现有的用户定义链。如果未用-X或--delete-chain选项指定链,则将删除所有用户定义的链。无法删除内置链,例如 filter 表中的 INPUT 或 OUTPUT 链。
iptables { -P | --policy } chain target
此形式的命令用于设置链的策略目标。例如,要将 INPUT 链的策略目标设置为 DROP,请使用以下命令
- iptables -P INPUT DROP
iptables { -E | --rename-chain } old-chain-name new-chain-name
此形式的命令用于重命名用户定义的链。
ipset
[edit | edit source]ipset 用于设置、维护和检查 Linux 内核中所谓的“IP 集”。IP 集通常包含一组 IP 地址,但根据其 "类型",也可以包含其他网络号集。
任何一个集合中的条目都可以绑定到另一个集合,从而允许进行复杂的匹配操作。
只有当没有 iptables 规则或其他集合引用集合时,才能删除(销毁)集合。
命令
[edit | edit source]这些选项指定要执行的特定操作。除非下面另有说明,否则命令行上只能指定其中一个。对于命令和选项名称的所有长版本,您只需要使用足够的字母来确保 ipset 可以将其与所有其他选项区分开来。
- -N setname 类型 类型特定选项
- --create setname 类型 类型特定选项
创建一个用 setname 标识并指定类型的集合。必须提供类型特定选项。
- -X [setname]
- --destroy [setname]
销毁指定的集合,如果未指定或指定了关键字 ":all:",则销毁所有集合。在销毁集合之前,将删除属于集合元素的所有绑定以及集合的默认绑定。如果集合仍然被引用,则不会执行任何操作。
- -F [setname]
- --flush [setname]
从指定的集合中删除所有条目,或者如果未指定或指定了关键字 ":all:",则刷新所有集合。绑定不受刷新操作的影响。
- -E from-setname to-setname
- --rename from-setname to-setname
重命名一个集合。用 to-setname 标识的集合必须不存在。
- -W from-setname to-setname
- --swap from-setname to-setname
交换 Linux 内核中引用的两个集合。指向 from-setname 内容的 iptables 规则或 ipset 绑定将指向 to-setname 的内容,反之亦然。这两个集合都必须存在。
- -L [setname]
- --list [setname]
列出指定集合的条目和绑定,或者如果未指定或指定了关键字 ":all:",则列出所有集合的条目和绑定。-n、--numeric 选项可用于禁止名称查找并生成数字输出。当给出 -s、--sorted 选项时,将按顺序列出条目(如果给定的集合类型支持该操作)。
- -S [setname]
- --save [setname]
将给定的集合保存到 stdout,如果未指定或指定了关键字 :all:,则将所有集合保存到 stdout,以—restore 可以读取的格式。
- -R
- --restore
恢复—save 生成的已保存会话。已保存的会话可以从 stdin 馈送。
生成会话文件时,请注意,支持的命令(create set、add element、bind)必须按严格顺序出现:首先创建集合,然后添加所有元素。然后创建下一个集合,添加其所有元素,依此类推。最后,您可以列出所有绑定命令。另外,这是一个恢复操作,因此要恢复的集合必须不存在。
-A, --add setname IP 将 IP 添加到集合。
-D, --del setname IP 从集合中删除 IP。
-T, --test setname IP 测试 IP 是否在集合中。如果测试的 IP 在集合中,则退出状态码为零,如果它不在集合中,则退出状态码为非零。
-T, --test setname IP—binding to-setname 测试属于集合的 IP 是否指向指定的绑定。如果绑定指向指定的集合,则退出状态码为零,否则为非零。可以使用关键字:default: 来测试集合的默认绑定。
-B, --bind setname IP—binding to-setname 将集合 setname 中的 IP 绑定到 to-setname。
-U, --unbind setname IP 删除属于集合 setname 中的 IP 的绑定。
-H, --help [settype] 打印帮助,如果指定了 settype,则打印 settype 特定的帮助。在 -B、-U 和 -T 命令中,您可以使用标记:default: 来绑定、取消绑定或测试集合的默认绑定,而不是 IP。在 -U 命令中,您可以使用标记:all: 来销毁集合中所有元素的绑定。
其他选项
可以指定以下附加选项
-b, --binding setname 该选项指定 -B 绑定命令的绑定的值,它是该命令的必需选项。您也可以在 -T 测试命令中使用它来测试绑定。
-s, --sorted 排序输出。列出集合时,条目按排序顺序列出。
-n, --numeric 数字输出。列出集合、绑定、IP 地址和端口号时,将以数字格式打印。默认情况下,程序将尝试将它们显示为主机名、网络名或服务(如果适用),这可能会触发缓慢的 DNS 查找。
-q, --quiet 抑制任何输出到 stdout 和 stderr。ipset 仍然会返回可能的错误。
ipset 支持以下集合类型
ipmap
ipmap 集合类型使用内存范围,其中每个位代表一个 IP 地址。ipmap 集合最多可以存储 65536(B 类网络)个 IP 地址。ipmap 集合类型非常快,内存消耗少,非常适合用于匹配某个范围内的特定 IP。使用—netmask 选项和 CIDR 网络掩码值在 0-32 之间时,在创建 ipmap 集合时,您可以存储和匹配网络地址:即,如果通过使用指定的网络掩码屏蔽地址得到的值可以在集合中找到,则 IP 地址将在集合中。
创建 ipmap 集合时要使用的选项
--from from-IP—to-IP 从指定的范围创建 ipmap 集合。--network IP/mask 从指定的网络创建 ipmap 集合。--netmask CIDR-netmask 当指定可选的—netmask 参数时,将存储网络地址而不是 IP 地址,并且 from-IP 参数必须是网络地址。
macipmap
macipmap 集合类型使用内存范围,其中每个 8 字节代表一个 IP 和一个 MAC 地址。macipmap 集合类型最多可以存储 65536(B 类网络)个带有 MAC 的 IP 地址。将条目添加到 macipmap 集合时,必须将条目指定为 IP%MAC。删除或测试 macipmap 条目时,%MAC 部分不是必需的。
创建 macipmap 集合时要使用的选项
--from from-IP—to-IP 从指定的范围创建 macipmap 集合。--network IP/mask 从指定的网络创建 macipmap 集合。--matchunset 当指定可选的—matchunset 参数时,即使尚未设置,可以存储在集合中的 IP 地址也将始终匹配。请注意,集合和 SET netfilter 内核模块始终使用数据包中的源 MAC 地址来匹配、添加或删除来自 macipmap 类型集合的条目。
portmap
portmap 集合类型使用内存范围,其中每个位代表一个端口。portmap 集合类型最多可以存储 65536 个端口。portmap 集合类型非常快,内存消耗少。
创建 portmap 集合时要使用的选项
--from from-port—to-port 从指定的范围创建 portmap 集合。
iphash
iphash 集合类型使用哈希表来存储 IP 地址。为了避免哈希冲突,使用双重哈希,并且作为最后手段,执行哈希表的动态增长。iphash 集合类型非常适合存储随机地址。通过在创建集合时使用—netmask 选项和 CIDR 网络掩码值在 0-32 之间,您可以存储和匹配网络地址而不是 IP 地址:即,如果屏蔽了指定网络掩码的值可以在集合中找到,则 IP 地址将在集合中。
创建 iphash 集合时要使用的选项
--hashsize hashsize 初始哈希表大小(默认值为 1024)--probes probes 在将 IP 添加到哈希表时尝试通过双重哈希解决冲突的次数(默认值为 8)。--resize percent 在将 IP 添加到哈希表后,如果在 probes 次双重哈希后无法执行,则按此百分比(默认值为 50)增加哈希表大小。--netmask CIDR-netmask 当指定可选的—netmask 参数时,将存储网络地址而不是 IP 地址。由值为零的 resize 参数创建的集合不会被调整大小。iphash 类型集合中的查找时间大约与 probes 参数的值线性增长。同时,较高的 probes 值会导致哈希表利用率更高,而较小的值会导致哈希表更大、更稀疏。
nethash
nethash 集合类型使用哈希表来存储不同大小的网络地址。ipset 命令中使用的 IP “地址” 必须采用 IP-address/cidr-size 的形式,其中 CIDR 块大小必须在 1-31 的包含范围内。为了避免哈希冲突,使用双重哈希,并且作为最后手段,执行哈希表的动态增长。
创建 nethash 集合时要使用的选项
--hashsize hashsize 初始哈希表大小(默认值为 1024)--probes probes 在将 IP 添加到哈希表时尝试通过双重哈希解决冲突的次数(默认值为 4)。--resize percent 在将 IP 添加到哈希表后,如果在将 IP 添加到哈希表后无法执行,则按此百分比(默认值为 50)增加哈希表大小。IP 地址将在 nethash 类型集合中,如果它在添加到集合的任何网络块中,并且匹配始终从最小的网络块大小(最具体的网络掩码)开始,一直到最大的网络块大小(最不具体的网络掩码)。当通过 SET netfilter 内核模块将 IP 地址添加到 nethash 集合或从集合中删除 IP 地址时,它将通过集合中可以找到的最小网络块大小进行添加或删除。
nethash 类型集合中的查找时间大约与 probes 参数的次数和哈希表中不同掩码参数的数量线性增长。否则,相同的速度和内存效率评论适用于此处,如 iphash 类型。
ipporthash
ipporthash 集合类型使用哈希表来存储 IP 地址和端口对。为了避免哈希冲突,使用双重哈希,并且作为最后手段,执行哈希表的动态增长。ipporthash 集合最多可以存储 65536(B 类网络)个 IP 地址以及所有可能的端口值。在 ipporthash 类型集合中添加、删除和测试值时,必须将条目指定为“IP%port”。
ipporthash 类型的集合评估集合匹配的两个 src/dst 参数和 SET 目标。
创建 ipporthash 集合时要使用的选项
--from from-IP—to-IP 从指定的范围创建 ipporthash 集合。--network IP/mask 从指定的网络创建 ipporthash 集合。--hashsize hashsize 初始哈希表大小(默认值为 1024)--probes probes 在将 IP 添加到哈希表时尝试通过双重哈希解决冲突的次数(默认值为 8)。--resize percent 在将 IP 添加到哈希表后,如果在 probes 次双重哈希后无法执行,则按此百分比(默认值为 50)增加哈希表大小。与 iphash 类型一样,相同的调整大小、速度和内存效率评论适用。
iptree
iptree 集合类型使用树来存储 IP 地址,可以选择使用超时值。创建 iptree 集合时要使用的选项:--timeout value 条目的超时值(以秒为单位)(默认值为 0)在将 IP 地址添加到集合时,可以使用语法 IP%timeout-value 将其添加到特定超时值。