
工程声学/人耳与声音感知
摘要: 本页面将简要概述人类听觉系统,换能器类比,以及与听觉系统特定特征相关的一些非线性效应。将介绍来自心理声学学科的结果。
人耳是一个小型物理装置,具有不成比例的大特性。一方面,它可以承受声压级接近 1kPa 的声音,这几乎是自然界中最响亮的声音,另一方面,它可以检测到对应于鼓膜位移约为氢原子直径十分之一的声压级。[1] 如果将大脑中进行的信息处理和它引起的生理反应包括在内,人们就会明白为什么人类听觉系统从二十世纪初开始就一直让研究人员头疼。
一些研究人员将听觉系统视为一个非常复杂的主动换能器;它首先以声学方式传递波信息,然后以机械方式,然后以流体动力学方式,最后以电动力学方式传递给大脑。[2] 其他人,比如传奇的乔治·冯·贝克西,则坚持认为,在考虑听觉系统的行为时,应该考虑活有机体的持续再生性质。[3]
然而,人类并不陌生于复杂的问题。毕竟,我们已经登上了月球,那么现在到底发生了什么?
为了探索任何物理系统的行为,需要一组描述该系统的变量。这些变量应该定义良好,并且自然地源于控制系统行为的物理原理。相同的物理原理也为任何研究人员提供了经过充分验证的方法来评估什么构成有效的测量。
此外,在任何行为良好的物理系统中,实验者都可以控制变量,以至于他或她可以保持大多数变量不变,并单独改变其中几个变量来评估它们之间的关系,并量化它们的依赖性。
此外,在任何线性系统中,叠加原理都成立,因此同时改变多个变量的总体效果等于从单独改变每个变量的同时保持其他所有变量不变观察到的各个贡献的线性组合。
上面提到的通常构成可以描述为非常快乐的研究人员。然而,当一个人着手评估人类听觉系统时,就会出现问题,因为听觉是一种感觉,就像所有其他感觉一样,它是一个玄妙的过程。为了解决这个问题,人们必须冒险进入心理物理学和心理测量原理的领域。众所周知,人们不能直接测量感觉,但人们可以测量感觉引起的反应。[4]
使用上述方法,人们可以测量诸如刚好可觉察的差异、可感知的兴奋、神经活动增加等量。然而,这些测量的有效性或相关性不能轻易地通过第一原理来确认。[1] 人类听觉系统的性质使得人们无法分离并独立地改变任何感兴趣的变量(无论它们是如何定义的),即使可以,叠加原理通常也不适用。
在承认量化听觉系统行为和开发听觉模型所涉及的困难之后,人们应该看看非线性的具体来源,以及这种行为对听觉系统施加的机制。可能没有比所谓的声反射、听觉反射或耳内反射更好的例子了。
人类的声反射是指中耳肌肉控制听骨(中耳的小骨头)的行为在强声刺激下趋于紧张,从而使内耳更硬,从而限制镫骨(链条中最后一块骨头)的运动。镫骨运动的这种减少相当于对通过中耳传递到内耳的振动的幅度进行实际的而不是感知的减少。这种反射有助于保护敏感的内耳在暴露于响亮声音时免受损害。
不幸的是,尽管速度很快,但听觉反射不是瞬时反应。对于低频,响应需要 20 到 40 毫秒才能引发,因此不能防止枪声和爆炸之类的响亮冲击声。[5] 随着听觉反射的开始,整个耳朵表现出明显的声阻抗变化,这在 1934 年被 Geffcken 观察到,并在随后的几年里被 Bekesy 和其他研究人员测量到。然而,有人认为,听觉反射的开始发生在非常高强度的声波下,因此它对感知的影响有限。[6] 另一方面,可以通过例如发声来自愿引发相同的反射。根据 Lawrence A. Kinsler 的说法,听觉系统产生的响应似乎主要归因于耳朵的机械特性,因此也归因于声音感知。[5] 不管听觉反射的确切性质是什么,或者它影响最大的确切范围是什么,这都超出了本文的范围。
- 压力传感器在特定位置测量声场强度的值,与人在同一位置感知同一声场的方式之间存在很大差异。
- 我们需要使用一个变量,让我们可以对我们认为响亮或强烈的声波进行赋值,以及关于如何测量这些量的指南。
- 虽然听觉反射的影响在更高的声强下可能更明显,但它不是一个阶跃函数。它会逐渐开始发挥作用,以及它改变感知的方式。
- 测量的听觉反射效果因人而异,并且受许多因素的影响。
声音的强度和响度是两个高度相互依赖的量。响度属于声音的心理属性,而强度是一个精确定义和可测量的物理量。由于它们之间的相似性,这两个量曾经被认为是一样的,因为如果增加特定声音的强度,声音就会变得更响亮。[4] 用最简单、最清楚的术语来说:强度是测量的声级,响度是感知的声级。
测量的声级用强度和声级来表示,而感知的声级用响度和响度级来表示。
声音强度定义为单位面积上的声功率,单位是瓦特每平方米。
![{\displaystyle I={\frac {Power}{UnitArea}}\quad \left[{\frac {W}{m^{2}}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/201e00e770fd0a7680151d75005007ec250b9edc)
然而,人耳能感知的声强范围从 1x10−12Wm−2 到 1x102Wm−2(超过此强度会导致永久性耳聋)。这使得最大值比最小值大 10 000 000 000 000 倍。[7]
为了更直观地理解并避免使用繁琐的数字,我们使用 **声强级** **IL**,它被定义为相对于 10x10−12 Wm−2 的声强,采用对数刻度,单位为分贝。
.
![{\displaystyle I_{L}=10\log \left({\frac {I}{I_{ref}}}\right)\quad [dB]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/95851f7f136fd8432303a4cb5fe0d9084929327c)
在空气中的平面波以及标准温度和平均压力下,声压和声强之间存在以下关系

其中 ρ 为空气密度,c 为空气中的声速。通过以下操作

右侧的表达式称为 **声压级**,它与声强级相同,但用声压表示。使用的参考压力为 20μPa。它非常接近在没有噪音的情况下空气中平均最低可听声压。[1] 需要注意的是,最小可听声压是针对多个受试者的平均值,因此对于一定比例的人群来说,负声压级是可感知的,即他们可以感知比参考压力更小的声压。选择的参考压力级通过上述关系对应于参考声强,使得 SPL 和 IL 相同。
“响亮”、“不太响亮”、“极其响亮” 等定性表达用于描述响度。尽管这些表达对于描述特定个体的感受是足够的,但它们在量化结果方面做得非常差。上述定性表达已经通过使用 **响度级** 和 **响度** 对于纯音(即正弦波)进行了量化。
特定测试音的 **响度级** 是响度的间接测量,它被定义为与测试音听起来一样响亮的 1000 Hz 纯音的 **声压级 (SPL)**。[1] 选择 1000 Hz 音调是任意的,并作为标准保留下来。响度级用方来测量。刚刚可听的 1000 Hz 音调的响度级被定义为 3 方,因为 1 kHz 音调的最小可感知 SPL 为 3 dB。方值增加是对数的,因为 SPL 是用分贝测量的。
**响度级** 在量化感受方面非常有用,但它无法提供关于不同响度级声音之间关系的信息。换句话说,它无法提供关于例如 20 方的声音比 50 方的声音响多少的信息。为了解决这个问题,我们使用 **响度**,它的单位是宋。**响度** 基于 40 dB,1000 Hz 纯音,被定义为响度为 1 宋。响度标度是通过增加或减少 1 kHz 音调的 SPL 直到它“听起来比以前响两倍”或“静音一半”等来推导出来的。响度不断减半创建了标度的其余部分。其余音调的 **响度** 是通过相同的等响度判断来确定的,这种判断提供了 **响度级**。[4]
响度和响度级最好用曲线图来表示,并且在绘制纯音的 SPL 时最为有用,这些曲线称为等响度曲线或 弗莱彻和芒森曲线,以早期研究者的名字命名,但自从这些测量首次进行以来,响度测量的技术已经发生了重大改变和标准化。
-
 等响度曲线
等响度曲线

关于上述曲线的一些观察结果
- 等响度曲线是连接等响度点的曲线。它们适用于持续时间超过 500 毫秒的声音,这些值是正常听力的平均值。[8]
- 由于使用的是 1000 Hz 音调作为标准,因此该音调在任何响度级的响度级都等于其 SPL。
- 音调的 SPL 是在受试者不在声场中测量,因为听者的存在会改变声场。
- 响度是在消声室中测量的,听者坐在距离声源超过 1 米的地方,它被定义为用于正面入射波。非正面入射波具有不同的特性。
- 注意曲线在 3 kHz 附近的“凹陷”。该频率对应于外耳的共振频率,并且也接近人类语音的中间频率。图表上的“凹陷”转化为对 3 kHz 附近的声音更高灵敏度。不幸的是,这也转化为来自该区域频率的更高损伤风险。
一些生物学知识
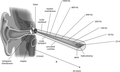
[edit | edit source]耳蜗
[edit | edit source]**耳蜗** 或内耳构成耳朵的流体动力学部分。它是一个由骨骼形成的小而空心的蜗牛形结构,充满无色液体。它的展开长度约为 35 毫米,横截面积在靠近内耳的一端约为 4 毫米2,在远端逐渐变细至约 1 毫米2。[1]
它充满 **两种** 不同的液体,这些液体被分成 **三个** 不同的通道,这些通道从镫骨的底部一直延伸到耳蜗的顶端,但是两个通道被瑞利膜隔开,瑞利膜是薄而灵活的,从流体力学角度来看可以忽略不计。[8] 振动直接从镫骨(三个听小骨中的最后一个)的基底板传递到所含液体中。耳蜗被中间的 **基底膜** 隔开,基底膜是部分骨质和部分胶状的膜。正是在这层膜上,柯蒂氏器和臭名昭著的 **毛细胞** 驻扎着。
-
 听觉系统和耳蜗
听觉系统和耳蜗 -
 三个充满液体的空腔
三个充满液体的空腔


如前所述,基底膜是一种柔性的胶状膜,纵向将耳蜗隔开。它是耳蜗隔膜的柔性部分(另一部分是骨质的),它包含大约 25000 个神经末梢,这些神经末梢连接到膜表面排列的大量毛细胞上。它从耳蜗底部延伸到耳蜗顶端之前,在此处它在蜗轴处终止。这形成了两个水动力学上不同的通道,镫骨基板连接到上通道入口处的 **卵圆窗**,而一个高度灵活的膜称为 **圆窗** 封闭下通道。两个通道在顶端通过 **蜗轴** 连接,蜗轴基本上是耳蜗隔膜上的一个间隙。
-
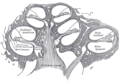 耳蜗纵向剖面图,显示基底膜的位置
耳蜗纵向剖面图,显示基底膜的位置 -
 耳蜗力学两种视图
耳蜗力学两种视图


传到镫骨的振动会在流体中产生声波,这些声波沿着上通道传播,穿过蜗轴并向上返回下通道。由于耳蜗壁相对坚硬,所含流体相对不可压缩,这会导致基底膜弯曲。为了平衡耳蜗内的压力,圆窗“鼓出”,从而提供压力释放。
基底膜从窄处开始,在卵圆窗附近宽度约为 0.04 毫米,然后在蜗轴附近扩大到约 0.5 毫米。这种宽度上的不均匀性以及圆窗提供的压力释放会导致基底膜在不同位置(距离卵圆窗的距离)沿膜振动,这取决于振动频率。这使得基底膜表现为声学滤波器,根据最大值的位移来分离传入声信号的组成频率。
-
 展开的耳蜗,带有基底膜
展开的耳蜗,带有基底膜

覆盖基底膜顶面的毛细胞是声波机械能转化为电脉冲链中的最后部分。这些细胞在柯蒂氏器(沿基底膜延伸)中排列成内排和外排,它们周围是被不同电位(突触)包围的带电细胞。[1][8]
-
 暴露毛发和毛细胞的横截面
暴露毛发和毛细胞的横截面 -
 耳蜗横截面,毛细胞可见
耳蜗横截面,毛细胞可见


如前所述,基底膜在受到声音输入时在不同位置表现出不同的振动最大值。由于这些激励,流体相对于膜产生平行运动。这种运动在从这些细胞突出的无数微小毛发上产生剪切力。这种扰动会在周围的带电细胞上产生电化学级联反应,从而产生向大脑发送信号的结果。
重要的是要注意,这些毛细胞不是均匀地分布在基底膜表面上,而是集中在离散的区域。由于不同的频率会导致基底膜的不同部位产生比其他部位更大的振动,这意味着我们可以感知到某些频率范围比其他频率范围更好,具体取决于基底膜上对应区域周围的毛细胞数量密度。这引入了离散性并为我们的听觉感官提供了一种最小分辨率,从而导致了一些有趣的非线性效应,这些效应将在不久后讨论。
-
 毛细胞在耳蜗上的排列。左=健康;右=模式缺陷
毛细胞在耳蜗上的排列。左=健康;右=模式缺陷

由于内耳的行为与带通滤波器的行为相似,上述频率组被称为 **临界带宽**。[2]
现在已经更多地介绍了内耳的工作原理,可以说明特异性听觉系统的更多特性,从一种相当普遍且在发生时非常明显的非线性效应开始。它是拍现象。
拍现象是多自由度系统的特征,其中各个自由度在一定程度上耦合在一起,并接收两个略微不同频率的谐波激励。激励可以按如下方式求和:[5]

由此产生的振动不再是简单的谐波。
内耳是一个连续系统,基底膜充当复杂的带通滤波器来分离频率。当一只或两只耳朵暴露在由两个频率略微不同的音调组成的声波中时,基底膜表面上毛细胞的不均匀分布和强定位会导致同一组(或临界带宽)毛细胞被入射声波的两个音调成分激发。
-
 拍
拍

因此,听众会将组合声音感知为单个频率音调,但强度会周期性变化。这被称为拍。
在它们的频率差值超过带宽之前,音调仍然无法区分。有趣的是,如果将两个音调分别呈现给两只耳朵,则不会发生拍,耳朵能够分辨出差异。[4]
- ↑ a b c d e f 声学,莱奥·L·贝拉内克 1993 年,版权:美国声学学会,第 13 章 听力、语音清晰度和心理声学标准
- ↑ a b 根据理论和实验得出的稳定声音的总体响度,沃尔顿·L·豪斯,美国宇航局参考版 1001
- ↑ 美国声学学会杂志第 23 卷第 5 期,1951 年 9 月,耳蜗隔膜的 DC 电位和能量平衡,GEORG V. Bekesy,心理声学实验室,哈佛大学,剑桥,马萨诸塞州,(1951 年 5 月 5 日收到)
- ↑ a b c d 听力测量,伊拉·J·赫希,麦格劳希尔图书公司,第一版,1952 年
- ↑ a b c 声学基础,劳伦斯·E·金斯勒,艾伦·B·科彭斯,第四版
- ↑ 人类的声反射,Aage R. Moller,J. Acoust. Soc. Am. 34, 1524 (1962), DOI:10.1121/1.1918384
- ↑ http://www.engineeringtoolbox.com/sound-intensity-d_712.html
- ↑ a b c Fastl Hugo 和 Eberhard Zwicker。心理声学:事实和模型。第三版。柏林:施普林格,2007 年。印刷。