
路由协议和架构/基于软件的包过滤
能够解析数据包中字段的软件,在各种应用程序中运行在集成电路或微处理器上。
- 交换机: 学习算法基于帧源和目标 MAC 地址,帧转发基于目标 MAC 地址;
- 路由器: 数据包转发基于源和目标 IP 地址;
- 防火墙: 如果与数据包字段匹配的规则,则会抛出相关的过滤操作(例如,丢弃);
- NAT: 它在传输中的每个数据包之间转换私有和公有 IP 地址以及 TCP/UDP 端口;
- URL 过滤: 它阻止来自/到黑名单中网站 URL 的 HTTP 流量;
- 协议栈: 操作系统将数据包传递到适当的网络层堆栈(例如 IPv4 或 IPv6),然后数据包传递到适当的传输层堆栈(例如 TCP 或 UDP),最后基于识别会话的五元组,数据包通过正确的套接字提供给应用程序;
- 数据包捕获: 用于流量捕获的应用程序(例如 Wireshark、tcpdump)可以设置过滤器以减少捕获的数据包数量。
包过滤系统的典型架构
[edit | edit source]
- 内核级组件
- 网络窃听器: 它拦截来自网卡的数据包并将它们传递给一个或多个[1]过滤堆栈;
- 数据包过滤器: 它只允许满足捕获应用程序指定的过滤器的包通过,从而提高捕获效率: 不必要的数据包立即被丢弃,只有较少数量的数据包被复制到内核缓冲区;
- 内核缓冲区: 它在数据包被传递到用户层之前存储数据包;
- 内核级 API: 它为用户层提供原语,通常ioctl系统调用,用于访问底层。
- 用户级组件
- 用户缓冲区: 它将数据包存储到用户应用程序的地址空间;
- 用户级库(例如 libpcap、WinPcap): 它导出与内核级 API 提供的原语相映射的函数,并提供高级编译器以动态创建要注入数据包过滤器的伪汇编代码。
主要的包过滤系统
[edit | edit source]CSPF
[edit | edit source]卡内基梅隆大学/斯坦福大学数据包过滤器(CSPF,1987)是第一个数据包过滤器,它与其他协议栈并行实现。
它引入了了一些关键改进
- 内核级实现: 由于避免了内核空间和用户空间之间上下文切换的成本,处理速度更快,尽管更容易破坏整个系统;
- 数据包批处理: 内核缓冲区不会立即将到达应用程序的数据包传递,而是等待存储一定数量的数据包,然后将它们一起复制到用户缓冲区以减少上下文切换次数;
- 虚拟机: 过滤器不再是硬编码的,而是用户级代码可以在运行时实例化一段伪汇编语言代码,指定过滤操作以确定数据包是否可以通过或必须被丢弃,以及数据包过滤器中的虚拟机,实际上由switch case在所有可能的指令上,模拟一个处理器,该处理器解释每个传输数据包的代码。
BPF/libpcap
[edit | edit source]伯克利数据包过滤器(BPF,1992)是第一个认真实现的数据包过滤器,历史上被 BSD 系统采用,至今仍在使用,与用户空间的libpcap库相结合。
- 架构
- 网络窃听器: 它集成在 NIC 驱动程序中,可以通过对捕获组件的显式调用来调用;
- 内核缓冲区: 它被分成两个独立的内存区域,以便内核级和用户级进程可以独立工作(第一个进程写入,第二个进程读取),而无需同步利用两个 CPU 内核并行工作
- 存储缓冲区是内核级进程写入的区域;
- 保留缓冲区是用户级进程读取的区域。
NPF/WinPcap
[edit | edit source]WinPcap 库(1998)最初由都灵理工大学开发,可以被认为是整个 BPF/libpcap 架构在 Windows 上的移植。
- 架构
- Netgroup 数据包过滤器(NPF): 它是内核级组件,包括
- 网络窃听器: 它位于 NIC 驱动程序的顶部,注册为标准协议(如 IPv4、IPv6)旁边的新的网络层协议;
- 数据包过滤器: 虚拟机是即时(JIT)编译器: 它不是解释代码,而是将其转换为 x86 处理器本地指令;
- 内核缓冲区: 它被实现为循环缓冲区: 内核级和用户级进程写入同一个内存区域,内核级进程覆盖用户级进程已经读取的数据→ 它优化了存储数据包的空间,但是
- 如果用户级进程读取数据的速度太慢,内核级进程可能会覆盖尚未读取的数据(缓存污染)→ 需要两个进程之间的同步: 写入进程需要定期检查包含当前读取位置的共享变量;
- 内存区域在 CPU 内核之间共享→ 循环缓冲区效率较低;
- Packet.dll: 它在用户层导出与操作系统无关的函数,这些函数与内核级 API 提供的原语相映射;
- Wpcap.dll: 它是应用程序直接交互的动态链接库
- 它为程序员提供用于访问底层的高级库函数(例如pcap_open_live(), pcap_setfilter(), pcap_next_ex()/pcap_loop());
- 它包括编译器,该编译器在给定用户定义的过滤器(例如字符串)时ip),创建要注入数据包过滤器的伪汇编代码(例如 "如果字段 'EtherType' 等于 0x800 则返回 true")以供 JIT 编译器使用;
- 它实现用户缓冲区。
- 新功能
- 统计模式: 它在内核中记录统计数据,无需任何上下文切换;
- 数据包注入: 通过网络接口发送数据包;
- 远程捕获: 激活远程服务器,捕获数据包并将其本地交付。
- 性能优化技术的演变。
-
 传统架构。
传统架构。 -
 具有共享缓冲区的架构。
具有共享缓冲区的架构。 -
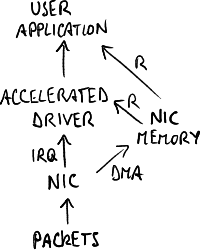 具有加速驱动的架构。
具有加速驱动的架构。



近年来,网络流量的增长速度快于计算机性能(内存、CPU)。 可以通过多种方式提高数据包处理性能
- 提高捕获性能: 提高将数据传递到软件的容量;
- 创建更智能的分析组件: 仅将最有趣的数据传递到软件(例如,URL 过滤器的 URL);
- 优化架构: 尝试利用应用程序特性来提高性能。
- 分析数据 (WinPcap 3.0, 64 字节长数据包)
- [49.02%] 网卡驱动程序和操作系统: 当进入网卡时,数据包需要花费大量时间才能到达捕获堆栈
- 网卡通过 DMA 将数据包传输到其内核内存区域(这不会使用 CPU);
- 网卡向网卡驱动程序发出 \textbf{中断} (IRQ),停止当前正在运行的程序;
- 网卡驱动程序将数据包从网卡内存复制到操作系统的内核内存区域(这会使用 CPU);
- 网卡驱动程序调用操作系统,将其控制权交给操作系统;
- 操作系统调用各种已注册的协议栈,包括捕获驱动程序;
- [17.70%] tap 处理: 捕获驱动程序在捕获堆栈开始时执行的操作(例如,接收数据包,设置中断);
- [8.53%] 时间戳: 数据包与其时间戳相关联;
- [3.45%] 数据包过滤器: 由于 JIT 编译器,过滤成本成比例地降低;
- 双重复制到缓冲区: 数据包越大,复制成本越高
- [9.48%] 内核缓冲区复制: 数据包从操作系统内存复制到内核缓冲区;
- [11.50%] 用户缓冲区复制: 数据包从内核缓冲区复制到用户缓冲区;
- [0.32%] 上下文切换: 由于数据包批处理,其成本微不足道。
在所有操作系统中,在某个输入速率下,到达捕获应用程序的数据包百分比不仅不再增加,而且会急剧下降,这是由于 **死锁**: 中断过于频繁,以至于操作系统没有时间从网卡内存读取数据包并将它们复制到内核缓冲区中,以便将它们传递给应用程序 → 系统处于活动状态并正在执行一些工作,但没有执行一些有用的工作。
存在几种解决方案来降低中断成本
- **中断缓解**(基于硬件):仅当接收一定数量的数据包时才触发中断(如果在一定时间内未达到最小阈值,则超时会避免饥饿);
- **中断批处理**(基于软件):当中断到达时,操作系统会处理到达的数据包,然后以轮询模式工作: 它会立即处理在此期间到达的后续数据包,直到没有更多数据包,并且可以重新启用网卡上的中断;
- **设备轮询**(例如 BSD [Luigi Rizzo]):操作系统不再等待中断,而是通过无限循环自动检查网卡内存 → 由于 CPU 内核始终在无限循环中繁忙,因此此解决方案适合在真正需要高性能的情况下使用。
存在两种解决方案来优化时间戳
- 近似时间戳: 实际时间仅有时会读取,时间戳基于自上次读取以来的时钟周期数 → 时间戳取决于处理器时钟频率,并且处理器的时钟频率越来越高;
- 硬件时间戳: 时间戳直接在网卡中实现 → 数据包到达软件时已带有其时间戳。
包含内核缓冲区的内核内存区域映射到用户空间(例如,通过nmap()) → 从内核缓冲区到用户缓冲区的复制不再需要:应用程序可以直接从 **共享缓冲区** 读取数据包。
- 实现
此解决方案已在 Luca Deri 的 nCap 中采用。
- 问题
- 安全性: 应用程序访问内核内存区域 → 它可能会损坏系统;
- 寻址: 内核缓冲区通过两个不同的寻址空间可见:内核空间中使用的地址与用户空间中使用的地址不同;
- 同步: 应用程序和操作系统需要对共享变量(例如,数据读写位置)进行操作。
操作系统并非旨在支持大型网络流量,而是经过设计来运行内存使用量有限的用户应用程序。 在到达捕获堆栈之前,每个数据包都会存储到操作系统的内存区域中,该区域是作为小型缓冲区的链接列表动态分配的(mbuf在 BSD 中,以及skbuf在 Linux 中) → 与用于存储任何大小数据包的大型静态分配缓冲区相比,迷你缓冲区的分配和释放成本过于昂贵。
捕获专用卡不再被操作系统识别,而是使用已集成到捕获堆栈中的 **加速驱动程序**: 网卡将数据包复制到其内核内存区域,并且应用程序可以直接从该内存区域读取,无需操作系统的介入。
- 实现
此解决方案已在 Luigi Rizzo 的 netmap 和 Luca Deri 的 DNA 中采用。
- 问题
- 应用程序: 其他协议栈(例如 TCP/IP 栈)消失 → 机器完全专用于捕获;
- 操作系统: 需要对操作系统进行侵入性更改;
- 网卡: 加速驱动程序与网卡紧密绑定 → 无法使用其他网卡型号;
- 性能: 瓶颈仍然是 PCI 总线的带宽;
- 时间戳: 由于软件延迟,它并不精确。
处理转移到内核空间,避免上下文切换到用户空间。
- 实现
此解决方案已在 Intel 数据平面开发套件 (DPDK) 中采用,目的是通过 Intel 硬件上的软件使网络设备可编程。
- 问题
- 数据包批处理: 由于数据包批处理,上下文切换成本非常低;
- 调试: 在用户空间更容易;
- 安全性: 整个应用程序使用内核内存;
- 编程: 在内核空间编写代码更困难。
处理直接由网卡执行(例如 Endace)
- 硬件处理: 它避免了 PCI 总线的瓶颈,限制了数据位移(即使性能提升有限);
- 时间戳精度: 没有软件延迟,并且基于 GPS → 这些网卡适用于跨地理区域广泛的网络进行捕获。
FFPF 提出了一种架构,该架构试图通过增加 用户空间中的并行性 来利用应用程序特性以更快地运行:捕获应用程序是多线程的,并在多核 CPU 上运行。
硬件可以帮助并行化:网卡可以向操作系统注册为多个适配器,并且每个适配器都是一个独立的逻辑队列,数据包会根据其分类从该队列中退出,该分类是通过 **硬件过滤器** 执行的,基于其字段(例如 MAC 地址、IP 地址、TCP/UDP 端口) → 多个软件片段可以并行从不同的逻辑队列读取。
- 应用
- 接收端扩展 (RSS): 分类基于会话标识符(五元组) → 属于同一会话的所有数据包将进入同一个队列 → 可以平衡 Web 服务器上的负载:
 B8. 内容交付网络#服务器负载均衡;
B8. 内容交付网络#服务器负载均衡; - 虚拟化: 服务器上的每个虚拟机 (VM) 都有不同的 MAC 地址 → 数据包将直接进入正确的 VM,而不会被操作系统 (管理程序) 触碰: C3. 软件定义网络介绍#网络功能虚拟化.
- ↑ 每个捕获应用程序都有自己的过滤堆栈,但它们都共享相同的网络监听器。