
统计分析:使用 R 的入门 / 第 1 章
图 1.1 显示了 R 统计包中可用的标准数据集之一。在 1920 年代,记录了以不同速度行驶的汽车的制动距离。分析速度和制动距离之间的关系可以通过更改超速法律、汽车设计等影响大量人的生活。其他数据集,例如有关医疗或环境信息的数据集,对人类以及我们对世界的理解有着更大的影响。但现实世界中的数据通常是“混乱的”,如该图所示。大多数人看到该图后很乐意得出结论,即速度和制动距离之间存在某种联系。然而,这不可能是全部故事,因为即使是在相同速度下,也会记录不同的制动距离。

这种直觉上合理的模式和混乱的组合也许是科学结果中最常见的现象之一。统计分析可以帮助我们澄清和判断我们认为看到的模式,以及从混乱中揭示可能难以辨别的影响。它可以用作解释我们周围世界的工具,也许同样重要的是,它可以用来说服他人我们解释的正确性。这种对明智判断和说服他人的强调很重要:理想情况下,统计学应该帮助清晰地解释,而不是靠论据来强迫。
关于统计分析的一个常见误解是,它必然是技术性的并且“难以理解”。事实上,“我不懂统计学”是一个经常听到的感叹。但如果一项分析只能被统计学家理解,那么它在很大程度上已经失败了。为了让一项分析说服受众,应该仔细、全面地给出一种或多种对特定情况的合理解释。然后可以利用对数据的统计分析(理想情况下,这些数据已被收集用于检验这些解释)来证明一个可以普遍接受的结论。作为一项规则,解释越简单——越 简约——就越值得优先考虑。因此,一个好的解释是,对于一位见多识广的观察者来说,它是合理的、可理解的,它可以做出明确的预测,但尽可能地简单。
本书旨在教你如何以统计的方式来制定和检验这样的“解释”。这是统计分析的基础。
与它具有许多相似之处的“科学方法”一样,是否存在一个普遍的“统计方法”[需要引用]也存在争议。然而,大多数统计分析都涉及质疑世界某一方面,提出对这些问题的潜在答案,然后通过提出统计模型来正式化这些解释,这些模型可以解释数据的特定方面。
因此,分析的三个主要部分是
- 决定你想要解决的问题(或者更笼统地说,分析的目标)
- 提出一些合理的解释,这些解释有可能回答这些问题
- 将这些解释形式化为统计模型
- 收集适当的数据
- (使用或多或少的技术方法)使用数据检验模型。
例如***
因此,你可能执行的大多数分析都显式或隐式地假设了潜在的“统计模型”。因此,理解统计模型以及它们所包含的内容对于理解统计学至关重要。
第 3 章将更详细地讨论统计模型,但在这里介绍一些一般概念是值得的。模型提供一些预测***。区别统计模型的是,该过程中也存在不确定性。因此,统计模型由两个组成部分组成:一个是固定的,另一个是捕捉不确定性的。这是
例如,我们可以回到图 1.1 中描述的情况。我们会多次回顾的一点是,对数据背景或上下文的良好理解对于任何分析都是必不可少的。在这种情况下,了解数据与汽车的速度和制动距离有关非常重要。我们关于驾驶的一般知识可以指导我们选择模型。特别是,我们可能猜测,假设速度对制动距离有影响(而不是相反)似乎是合理的。将速度视为由其他因素决定,并且超出了我们分析范围似乎是合理的***。
因此,一个初始的、合理的模型可能会假设制动距离由速度加上某种随机误差决定。为了精确地建模,为了根据一组速度构建一组假想的制动距离,我们需要更加精确。特别是,我们需要指定速度如何影响距离,以及误差是什么样子***。
稍后我们将看到如何用数学方式指定这一点。目前,我们将用图形和模拟的方式来完成
通常假设“正态”误差 ****
例如,也许根本没有影响:无论速度如何,制动距离都是固定的:距离变化的唯一原因是由于随机误差。=> 用图形显示
我们需要比这更精确:我们
统计模型中最重要的方面之一是,当模型在图 1.2(a-d)中显示时,这是合理的。在所有四个图形中,都提出了不同的统计模型:每个模型的预测部分用红色线显示,不确定性(归因于机会或误差的波动)用浅蓝色线显示。在所有情况下,该模型都假设不确定性全部存在于制动距离的影响中(浅蓝色线全部是垂直的)。
为了单独显示不确定性,每个图形中的右侧图形显示了残差***。
- 图 1.2:适合图 1.1 中数据的各种统计模型
-
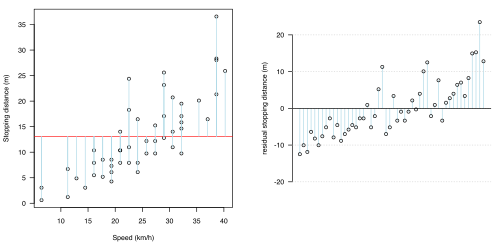 (a)无关联
(a)无关联 -
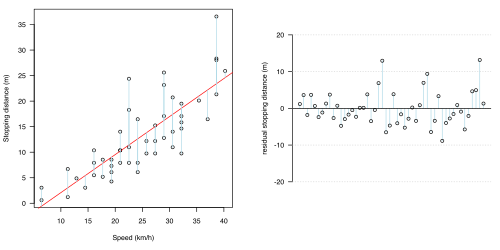 (b)直线
(b)直线 -
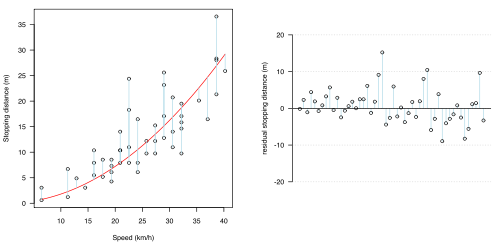 (c)平方(简单二次)关系
(c)平方(简单二次)关系 -
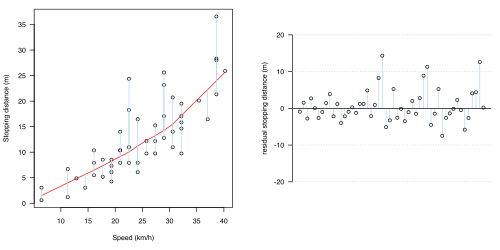 (d)使用局部平滑(LoWeSS)拟合
(d)使用局部平滑(LoWeSS)拟合




* 直线(橙色)。线性关系可能是解释之间的关系的最简单方法,这就是为什么***。对该模式的最简单解释是,制动距离与速度成正比,因此,每增加一英里/小时,制动距离就会增加一个固定量:在图形上,这表示图上的直线。这很常见。
- 曲线(红色)。然而,这还没有考虑到任何 : 也许。如前所述,这不足以解释所有数据:可能不清楚 lowess 是一个模型 ****。
“cars”示例突出了在进行统计时,事先了解信息的重要性。数据不应该被视为纯粹的“数字”,而应该在上下文中考虑。在这里,因为我们知道数据是相对容易理解的物理系统的结果,所以我们应该被引导着问是否期望特定的关系,这会鼓励我们使用简单的二次拟合。
因此,在任何分析中,了解数据至关重要:了解它们从哪里来,它们如何与现实世界相关,以及——通过绘图或其他形式的“探索性数据分析”——它们是什么样子。事实上,绘制数据是统计分析中最基本的技术之一:它是一个揭示模式并说服他人的强大工具。如果有必要,可以使用更正式的数学技术来对其进行补充。本书中使用图形的目的有两个:它们不仅可以用于探索数据,而且正式的统计方法通常可以通过图形方式来理解和描绘,而不是大量使用数学。这是本书的主要目标之一。
包
一些包应该始终在 R 中可用,并且其中许多在 R 会话开始时自动加载。这些包括“base”包(其中定义了max()和sqrt()函数)、“utils”包(其中定义了RSiteSearch()和citation())、“graphics”包(允许生成绘图)以及“stats”包(提供广泛的统计功能)。总的来说,默认包允许您进行大量的统计分析。
library()函数将其加载到 R 中。library("datasets") #Load the already installed "datasets" package
cars #Having loaded "datasets", the "cars" object (containing a set of data) is now available
library("vioplot") #Try loading the "vioplot" package: will probably fail as it is not installed by default
install.packages("vioplot") #This is one way of installing the package. There are other ways too.
library("vioplot") #This should now work
example("vioplot") #produces some pretty graphics. Don't worry about what they mean for the time being> library(datasets) # 加载数据集包(实际上,它可能已经被加载了) > cars # 显示其中一个数据集:有关更多信息,请参阅 ?car
speed dist
1 4 2 2 4 10 3 7 4 4 7 22 5 8 16 6 9 10 7 10 18 8 10 26 9 10 34 10 11 17 11 11 28 12 12 14 13 12 20 14 12 24 15 12 28 16 13 26 17 13 34 18 13 34 19 13 46 20 14 26 21 14 36 22 14 60 23 14 80 24 15 20 25 15 26 26 15 54 27 16 32 28 16 40 29 17 32 30 17 40 31 17 50 32 18 42 33 18 56 34 18 76 35 18 84 36 19 36 37 19 46 38 19 68 39 20 32 40 20 48 41 20 52 42 20 56 43 20 64 44 22 66 45 23 54 46 24 70 47 24 92 48 24 93 49 24 120 50 25 85 > library(vioplot) # 尝试加载“vioplot”包:这可能会失败,因为它不是默认安装的 错误: 在 library(vioplot) 中: 没有名为 ‘vioplot’ 的包 > install.packages("vioplot") # 这是安装包的一种方法。还有其他方法。 同时安装依赖项 ‘sm’
尝试 URL 'http://cran.uk.r-project.org/bin/macosx/universal/contrib/2.8/sm_2.2-3.tgz' 内容类型 'application/x-gzip' 长度 306188 字节 (299 Kb) 已打开 URL
=======================
已下载 299 Kb
尝试 URL 'http://cran.uk.r-project.org/bin/macosx/universal/contrib/2.8/vioplot_0.2.tgz' 内容类型 'application/x-gzip' 长度 9677 字节 已打开 URL
=======================
已下载 9677 字节
已下载的包位于 /tmp/RtmpR28hpQ/downloaded_packages > library(vioplot) # 这现在应该可以工作 加载所需的包:sm 包 `sm`,版本 2.2-3;版权所有 (C) 1997、2000、2005、2007 A.W.Bowman & A.Azzalini 键入 help(sm) 以获取摘要信息 > example(vioplot) # 生成一些漂亮的图形。暂时不必担心它们的意思
vioplt> # 箱线图与小提琴图 vioplt> par(mfrow=c(2,1))
vioplt> mu<-2
vioplt> si<-0.6
vioplt> bimodal<-c(rnorm(1000,-mu,si),rnorm(1000,mu,si))
vioplt> uniform<-runif(2000,-4,4)
vioplt> normal<-rnorm(2000,0,3)
vioplt> vioplot(bimodal,uniform,normal) 按 <回车> 查看下一张图
vioplt> boxplot(bimodal,uniform,normal)
vioplt> # 添加到现有图中 vioplt> x <- rnorm(100)
vioplt> y <- rnorm(100)
vioplt> plot(x, y, xlim=c(-5,5), ylim=c(-5,5)) 按 <回车> 查看下一张图
vioplt> vioplot(x, col="tomato", horizontal=TRUE, at=-4, add=TRUE,lty=2, rectCol="gray")
vioplt> vioplot(y, col="cyan", horizontal=FALSE, at=-4, add=TRUE,lty=2)
install.packages()以这种方式安装包,也应该安装依赖项[1]。还有几种其他安装包的方法。如果您通过在 Unix 命令行上键入“R”来启动 R,那么您可以通过从命令行运行“R CMD INSTALL packagename”来安装包(请参阅?INSTALL)。如果您使用图形用户界面(例如在 Macintosh 或 Windows 下)运行 R,那么您通常可以通过使用屏幕菜单来安装包。请注意,这些方法可能无法安装其他依赖包。
您只需要在安装包时遇到问题时才需要阅读以下内容。 如果一个包还没有安装,并且您在尝试安装它时遇到问题(例如,当调用 install.packages("vioplot")时),这可能是由于以下原因之一
|
图形
在 R 中生成绘图有两种主要方法
- 传统的 R 图形。这个基本的图形框架是我们将在本主题中介绍的内容。我们将使用它来生成与图 1.1 和 1.2 中相似的绘图。
- “Trellis”图形。这是一种更复杂的框架,适用于在一页上生成多个类似的绘图。在 R 中,此功能由“lattice”包提供(键入
help("Lattice", package=lattice)以获取详细信息)。
如何在后面的章节中生成特定类型的绘图的详细信息;本主题仅介绍最基本原理,其中有三个主要原理需要注意
- 在 R 中,绘图是通过键入特定的图形命令来生成的。这些命令有两种类型
- 设置完全新绘图的命令。此类型最常见的函数称为
plot()。在最简单的情况下,这可能会用新的绘图替换任何以前的绘图。 - 向现有绘图添加图形(线条、文本、点等)的命令。许多函数可以做到这一点:最有用的函数是
lines()、abline()、points()和text()。
- 设置完全新绘图的命令。此类型最常见的函数称为
- R 始终将图形输出到设备。通常这是屏幕上的一个窗口,但它可以是 pdf 或其他图形文件(可以在
?device中找到完整列表)。这是将绘图保存到文档等中的一种方法。要将图形保存到(例如)pdf 文件中,您需要使用pdf()激活新的 pdf 设备,运行您的正常图形命令,然后使用dev.off()关闭设备。这在下述最后一个示例中进行了说明。 - 根据
plot()的第一个参数,会触发不同的函数。默认情况下,这些函数旨在生成合理的结果。例如,如果它接受一个函数,例如sqrt函数,plot()将生成x对sqrt(x)的图形;如果它接受一个数据集,它将尝试以合理的方式绘制数据点(有关更多详细信息,请参阅?plot.function和?plot.data.frame)。诸如颜色、样式和项目大小以及轴标签、标题等图形细节,可以通过plot()函数的进一步参数来控制[3]。
plot(sqrt) #Here we use plot() to plot a function
plot(cars) #Here a dataset (axis names are taken from column names)
###Adding to an existing plot usually requires us to specify where to add
abline(a=-17.6, b=3.9, col="red") #abline() adds a straight line (a:intercept, b:slope)
lines(lowess(cars), col="blue") #lines() adds a sequence of joined-up lines
text(15, 34, "Smoothed (lowess) line", srt=30, col="blue") #text() adds text at the given location
text(15, 45, "Straight line (slope 3.9, intercept -17.6)", srt=32, col="red") #(srt rotates)
title("1920s car stopping distances (from the 'cars' dataset)")
###plot() takes lots of additional arguments (e.g. we can change to log axes), some examples here
plot(cars, main="Cars data", xlab="Speed (mph)", ylab="Distance (ft)", pch=4, col="blue", log="xy")
grid() #Add dotted lines to the plot to form a background grid
lines(lowess(cars), col="red") #Add a smoothed (lowess) line to the plot
###to plot to a pdf file, simply switch to a pdf device first, then issue the same commands
pdf("car_plot.pdf", width=8, height=8) #Open a pdf device (creates a file)
plot(cars, main="Cars data", xlab="Speed (mph)", ylab="Distance (ft)", pch=4, col="blue", log="xy")
grid() #Add dotted lines to the pdf to form a background grid
lines(lowess(cars), col="red") #Add a smoothed (lowess) line to the plot
dev.off() #Close the pdf device


一个简单的 R 会话
a ~ b + c 的符号,表示 a 由 b 和 c 预测)。plot(dist ~ speed, data=cars) #A common way of creating a specific plot is via a model formula
straight.line.model <- lm(dist~speed, data=cars) #This creates and stores a model ("lm" means "Linear Model").
abline(straight.line.model, col="red") #"abline" will also plot a straight line from a model
straight.line.model #Show model predictions (estimated slope & intercept of the line)
科学方法
[edit | edit source]统计学家不能逃避搞清楚科学推理原则的责任,同样地,任何其他思考的人也不能逃避类似的义务。——R. A. Fisher
本书重点介绍统计学在 科学方法 中的重要作用。从根本上说,科学涉及仔细测试一系列合理的解释,或者说是“假设”,这些解释声称解释观察到的现象。通常,这是通过提出合理的假设,然后尝试通过仔细的实验或数据收集来消除其中一个或多个假设来完成的(这被称为 假设演绎法)。这意味着对科学假设的基本要求是它可以被证明是错误的:用 Popper 的话来说,它是“可证伪的”。在本章中,我们将看到逻辑上不可能“证明”一个假设是正确的;尽管如此,一个假设通过的测试越多,我们就越应该相信它。
理想情况下,科学研究涉及一个重复的过程,包括生成假设、消除尽可能多的假设,并提炼剩余的假设,这个过程被称为“强推断”(引用 Platt)。这里涉及两个截然不同的步骤:一个相当推测性的步骤,其中生成或提炼假设,以及一个严格逻辑性的步骤,其中消除假设。
这两个步骤在统计分析中都有其对应物。与假设检验有关的统计分支旨在识别哪些假设似乎不太可能,因此可能被消除。与探索性分析有关的统计分支旨在识别数据集的合理解释。虽然我们将分别开始讨论这些技术,但应强调,在实践中,这种区别并不那么明确。统计实践的这两个分支最好被视为研究人员可用的技术连续谱的两个极端。例如,许多假设涉及数值参数,例如最佳拟合线的斜率。对这些参数的统计估计可以被视为对假设的检验,但也可以被视为对事实的提炼或甚至新颖解释的建议。
假设检验
[edit | edit source]为了适当地检验一个假设,需要收集正确类型的数据。事实上,有针对性地收集数据和(如果可能)仔细设计实验,可能是科学中最重要的过程。这并不难。例如,假设我们的假设是(由于遗传原因)一个人不可能同时拥有金发和棕色眼睛。这个假设可以通过对拥有这种特征组合的人的单一观察来反驳。
Eye Hair Brown Blue Hazel Green Black 68 20 15 5 Brown 119 84 54 29 Red 26 17 14 14 Blond 7 94 10 16 |
表 1.1 显示了 1974 年对特拉华大学学生的一项调查的结果[4]。与任何测试一样,我们需要对这些数据做出一些假设,例如,染发学生没有被包括在内,或者列在了他们原来的头发颜色下。如果是这样,那么我们可以立即看到,我们可以拒绝金发&棕色:不可能的假设:有 7 名学生有棕色眼睛和金发[5]。
但是,想象一下,如果调查没有发现任何棕色眼睛和金发的学生。虽然这与我们的假设一致,但它不足以证明它是正确的。可能是棕色眼睛和金发非常罕见,我们没有看到任何人是纯粹的巧合。这是一个普遍的问题。不可能确定一个假设是正确的:可能总会有另一个非常相似的解释来解释相同的观察结果。
然而,正如在这个例子中看到的,可以拒绝假设。因此,科学依靠消除假设。因此,科学家经常构建一个或多个他们认为不是这样,仅仅是为了被拒绝的假设。如果一项研究的目的是让人们相信一个特定的理论或假设,那么一个好的方法是定义包含尽可能多的可以预见的合理的替代解释的假设。如果所有这些都可以被反驳,那么剩下的原始假设就会更有说服力。
零假设
[edit | edit source]在大多数科学观察中,都存在一定程度的偶然性[6],因此尝试消除的最重要的假设——至少最初——是观察到的数据仅仅是由于偶然因素造成的。这通常被称为零假设。
在我们最初的例子中,零假设相对明显:它是头发和眼睛颜色之间没有关联(任何看似关联的都是纯粹的巧合)。但是,构建一个合适的零假设并不总是那么容易。以下是我们将在后面研究的三个例子,从简单到高度复杂不等。
- 医院出生的孩子的性别比例(例如,1997 年 12 月 18 日在澳大利亚布里斯班的 Mater Mother's 医院,出生了 44 个孩子[7],其中 18 个是女性)。一个合理的零假设可能是,无论性别如何,男性和女性的可能性都相同。由于已知人类通常具有男性偏向的性别比例,因此不同的零假设(例如 51% 的男性)可能更合理。
- 图 1.1 中看到的汽车速度和停车距离之间的关系。一个合理的零假设可能是,汽车的速度与其停车距离之间没有关系。但是,汽车停车距离(x 和 y 之间没有“关联”) - 更难,因为误差分布未知。以下是一种方法:例如,可以取 x 的秩和 y 的秩。或者抽样。
在这两种情况下,我们都需要*建模*零假设:如果
- 英国 1969-1985 年汽车死亡和重伤人数。 图 1.2 显示安全带 **** 更复杂的零模型 - 例如安全带 - 如果我们拟合一条直线,我们需要对该线的变化做出一些假设。或者我们可以将实际值视为代表该变化。这是一个更复杂的模型,影响了英国大部分人口,即 1983 年 1 月 31 日生效的强制使用汽车安全带的法律。零模型涉及其他因素(例如汽油价格)
{kind=link}
只要有足够的信息,我们就可以对零假设进行建模。**针对不同示例需要什么**。由于存在随机误差,我们需要多次这样做。我们将看到,许多统计学都依赖于根据零假设给出类似于观察结果的频率来拒绝零假设。
其他情况也是一样,例如安全带???比较模型


假设可能不是简单的“是”或“否”问题,而是更复杂的,例如:
数据表明的性别比例是多少?(这很简单,但我们对这个估计的准确性有多大信心?)
汽车:我们相信速度和刹车距离之间存在线性关系:线的斜率是多少(但也许物理学表明不同的关系 - 直线通常是默认值) - 这里我们已经做出了一些模型选择。
MLE 简要描述“如果模型是正确的,这些参数的最可能值是什么?”
有无数的模型存在。结合良好的理解和/简约性/,可以用来构建假设和*模型*。DF?
例如,是否有比直线拟合更好的想法?
这是否合理(例如,如果不能小于 0)
安斯库姆
异常值???残差(可能不是)
交互作用怎么样?泰坦尼克号的性别与等级?
使用颜色来区分类型
人眼擅长发现模式(但......即使没有模式)。例如,时间序列
即使我们有预测(模型),它与假设的拟合程度如何?
哪些是重要的(与显著因素相反)因素?
应该有足够的背景来描述来自[[2]]
每个实验只是一个数据点吗?等等?
- ↑ 实际上,细节稍微复杂一些,取决于是否有一个默认位置来安装软件包,请参见
?install.packages - ↑ 目前还没有介绍足够的 R 来完全解释本章中使用的绘图命令。不过,对于那些感兴趣的人来说,对于任何绘图,用于生成它的命令都列在图像摘要中(可以通过点击图像查看)。
- ↑ 不幸的是,可用的众多参数的细节(其中许多是其他图形生成例程共有的)散布在多个帮助文件中。例如,要查看对数据集调用时
plot()的选项,请参见?plot、?plot.default和?par。要查看对函数调用时plot()的选项,请参见?plot.function。在帮助文件中列出了用于指定各种绘图符号的pch参数的数字points()(用于向绘图添加点的函数):可以通过example(points)查看它们。 - ↑ 来自 Snee (1974) The American Statistician, 28, 9–12。完整的参考文献可以在 R 中通过输入 ?HairEyeColor 找到。此处的表格已在性别上汇总,如
example(HairEyeColor)
- ↑ 当假设很简单并且只有少量数据像这样时,以表格形式呈现它通常与绘图一样有用
- ↑ 这可能是真正的随机,也可能是由于我们不知道的因素造成的
- ↑ 见[[1]]