← 微积分 | 群论 →
正如我们在核心课程的统计学和概率论部分中学到的,期望值  ,或分布 "X" 的均值
,或分布 "X" 的均值  是
是

分布的方差定义为

如果 X 是离散的,方差可以定义为

如果对一个分布进行平移和缩放,均值和方差必须发生变化。这些值根据以下公式变化


注意,方差不受 *b* 的值影响,因为分布的方差永远不会因分布的平移而改变。只有代表分布水平拉伸的值 *a* 会修改分布的范围。
当一个人对随机变量 *X* 进行多次采样时,这些采样通常是独立的随机变量。在这种情况下,必须以不同的方式处理分布。


注意,方差总是叠加,而不是减去。此外,随机变量不一定来自同一个总体 *X*。
这些规则也适用于包含 *n* 个独立随机变量的情况。


该规则的推导超出了本课程大纲的范围。

方差的无偏估计量通过将原始方差乘以n/(n-1)来计算
二项式,B(n,p)
当X~B(n,p)时,P(X=x)表示在进行n次试验时获得x次成功的概率,每次试验的成功概率为p。
适用于
- 只有两种可能的结果
- 试验次数固定
- 每次试验与其他试验的结果无关
- 每次试验的概率保持不变。
负二项式,NB(r,p)
对达到r次成功所需的伯努利试验B(1,p)次数进行建模。概率质量函数中的组合系数仅仅是为了说明获得如此多次成功的排列方式数量。
几何分布,Geo(p)
对获得第一次成功所需的伯努利试验B(1,p)次数进行建模,即类似于NB(1,p)。不需要组合系数,因为一旦获得第一次成功,"计数"就会停止。因此,结果只有一个可能的排列。
泊松分布,Po(m)
泊松分布测量以下情况下的成功次数:
例如,每小时可能会有大量的电话呼入,但如果平均每小时两次,则这种可能性很小。注意:这假设m是恒定的,但在实际情况下并非如此(例如,电话呼入的频率取决于一天中的时间、一周中的哪天等)。此类问题通常涉及时间间隔之间的转换,例如,如果平均每小时两次呼入,并且需要知道 5 小时内特定次数呼入的概率,则使用的平均值为 10。此外,该分布的特定之处在于 E(x) = Var(x)。
这些可以遵循任何函数,其中
 对于所有
对于所有  f(x) 的范围。
f(x) 的范围。 如果
如果  的定义域是
的定义域是  。
。
此外,x 可以是任何值  ,它也在 的定义域内。累积频率是通过积分 计算的。
,它也在 的定义域内。累积频率是通过积分 计算的。
此外,大纲要求了解三种特定的连续概率分布。
指数分布,Exp(λ)
此分布对泊松分布中事件(假设为瞬时)之间的预期间隔进行建模。例如,对于 Po(2) 每小时的呼叫,每小时的预期呼叫次数为 2;指数分布的预期值, ,是半小时。
,是半小时。
指数分布也可以看作是几何分布的连续等价物,它对第一次成功之前的時間进行建模。
正态分布,N(μ,σ2)
这是最有趣的分布,也是与统计选项最相关的分布。由于中心极限定理,统计选项的大部分内容都基于正态分布。在关于正态分布的问题中,问题必须说明手头的數據“遵循正态分布”、“是正态分布的”等。这使得它易于识别。
标准正态变量Z 遵循该分布,是一种转换为Z 分数的方法,这对于计算置信区间和假设检验很重要。
正态分布对二项分布的近似
对于n 的较大值,X~B(n,p) 可以近似为 X~N(np,npq)。(这可以在直方图上显示。)
对于n 应该有多大有不同的估计;大于 5 通常是一个很好的近似,但 IB 说明  和
和  作为规则。在不满足这些条件的情况下,应明确说明近似值不好。
作为规则。在不满足这些条件的情况下,应明确说明近似值不好。
每个分布的方程式、函数和符号汇总如下所示。
| 分布 |
符号 |
概率质量函数 |
平均值 |
方差 |
| 二项分布 |
X~B(n,p) |
 对于 对于  |
 |

|
| 泊松分布 |
X~Pois(m) |
 for for  |
 |
|
| 几何分布 |
X~Geo(p) |
 for for  |
 |

|
| 负二项分布 |
X~NB(r,p) |
 for for  |
 |

|
| 分布 |
符号 |
概率密度函数 |
平均值 |
方差 |
| 指数分布 |
X~Exp( ) ) |
 |
|

|
| 正态 |
X~N( ) ) |
 |
|

|
通常,组合变量很有用,例如确定 的概率。这是通过求解不等式并基于一个新变量来实现的,例如
的概率。这是通过求解不等式并基于一个新变量来实现的,例如 在随机变量大小上。
在随机变量大小上。



现在我们需要找到,使用以下规则:


请注意,方差始终相加。在尝试组合变量之前,将标准差转换为方差也很重要。
问题还讨论了进行多次选择的组合。请注意以下区别:
 和
和 .
.
在第一个中,进行了四次独立选择。方差变为 .
.
其次,一次抽取的价值乘以四。在这种情况下,方差为  。
。
简而言之,尽管具有相同的 μ 和 σ,但应将不同的抽取视为独立的变量。
从非正态总体  中抽取样本,其平均值为μ 方差为σ2,这些样本的平均值将正态分布为
中抽取样本,其平均值为μ 方差为σ2,这些样本的平均值将正态分布为  ,其中n 是每个样本所基于的数据点数量(样本量)。当
,其中n 是每个样本所基于的数据点数量(样本量)。当  时,这适用。
时,这适用。
这些样本必须是独立的。虽然不需要证明中心极限定理,但了解它源于二项分布可能会有所帮助:要么  要么
要么  。概率是恒定且独立的,这意味着样本均值由二项式函数描述。我们已经知道通过二项分布的正态近似,当样本量足够大时,分布将近似正态。
。概率是恒定且独立的,这意味着样本均值由二项式函数描述。我们已经知道通过二项分布的正态近似,当样本量足够大时,分布将近似正态。
对于样本量 ,这是一个可靠的近似值。请注意,方差, ,正态分布的方差随着n 的增大而减小,这意味着概率分布将更窄,即更精确。使用中心极限定理时,正态分布的“标准差”,
,正态分布的方差随着n 的增大而减小,这意味着概率分布将更窄,即更精确。使用中心极限定理时,正态分布的“标准差”, ,也被称为抽样误差 或标准误差。
,也被称为抽样误差 或标准误差。
具有大样本量的比例也遵循正态分布。遵循与样本均值类似的逻辑,样本的比例可以是成功或失败。这种概率被认为是固定的,这意味着分布是二项式分布。当样本量足够大时,因此存在一个正态分布,其中  ,样本比例
,样本比例

如果p 是成功者的真实比例,n 是样本量,那么X~B(n,p)。因此,我们可以证明
- 期望值

- 方差

根据中心极限定理,我们可以说对于较大的n值, .
.
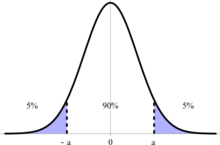 90% 置信区间。90% 的数据在 0±a 之内。
90% 置信区间。90% 的数据在 0±a 之内。
置信区间是根据分布的平均值测量的一个范围,在这个范围内,一定比例的样本位于其中。它通常用百分比表示,例如说“90% 的样本重量为 2±0.01 公斤”。
置信区间对样本均值和比例的计算方式相同。在每种情况下,令  或 。当总体方差未知时,会出现差异。下面将探讨这两种情况。
或 。当总体方差未知时,会出现差异。下面将探讨这两种情况。
数据手册给出了置信区间的表达式:
 (当n≥30时)。
(当n≥30时)。
这个相同的表达式只是用样本的标准分布表示:
 (当np≥10或nq≥10时)。
(当np≥10或nq≥10时)。
 是对应置信区间百分比的z分数。可以使用数据手册最后几页的表格或使用计算器上的 invNorm 函数查找。但是,请注意,输入 invNorm(.9) 不会给出 90% 置信区间的Z分数。剩下的 10% 必须平均分配到目标范围的平均值之上和之下,目标范围在平均值的 90% 之内。因此,z = invNorm(0.95)。这可以在上面的插图中清楚地看到 - 我们想找到a的值,因此应该使用 0.95 或 0.05。这与双尾检验(下面描述)的概念相同 - 如果我们说 90% 的值低于某个值,那么我们将使用 invNorm(0.9)。
是对应置信区间百分比的z分数。可以使用数据手册最后几页的表格或使用计算器上的 invNorm 函数查找。但是,请注意,输入 invNorm(.9) 不会给出 90% 置信区间的Z分数。剩下的 10% 必须平均分配到目标范围的平均值之上和之下,目标范围在平均值的 90% 之内。因此,z = invNorm(0.95)。这可以在上面的插图中清楚地看到 - 我们想找到a的值,因此应该使用 0.95 或 0.05。这与双尾检验(下面描述)的概念相同 - 如果我们说 90% 的值低于某个值,那么我们将使用 invNorm(0.9)。
计算器功能
ZInterval:输入一组数据或统计数据。请注意,在这两种情况下,都明确要求 σ。置信水平作为分数。使用数据时,选择列表名称并设置频率=1。
1-PropZInt:x 是n 次试验中的成功次数。置信水平作为分数。
当总体标准差 σ 未知时,我们必须使用样本数据来估计它。  用于表示 σ。请注意,样本标准差
用于表示 σ。请注意,样本标准差  可能在不知道总体标准差的情况下就已知。当 σ 已知时,我们说
可能在不知道总体标准差的情况下就已知。当 σ 已知时,我们说
 ,标准正态分布 N(0,1)。同样地,当 σ 未知时的分布是
,标准正态分布 N(0,1)。同样地,当 σ 未知时的分布是
 ,称为 t 分布。它只是标准正态曲线 N(0,1) 的一个“更胖”版本。
,称为 t 分布。它只是标准正态曲线 N(0,1) 的一个“更胖”版本。
使用 t 分布时,请说明自由度:ν = n-1,其中,通常情况下,n 是样本大小。(这在假设检验中具有重要意义。)
计算器函数
TInterval:数据或统计量。使用数据时,与 ZInterval 相同的输入方法。请注意, 等于
等于  ,必须使用样本标准差 通过
,必须使用样本标准差 通过  (来自数据手册)进行手动计算。
(来自数据手册)进行手动计算。
为了使估计正确,样本的大小必须足够大。随着 n 的增加,方差下降,精度提高(分布变窄)。
以下示例取自 Haese & Harris 的 IBDP Mathematics (Options)
“如果我们希望 98% 地确信样本均值与总体均值之间的差值小于 0.3,并且知道总体标准差 σ = 1.365,那么样本大小应该多大?”
这意味着  [其中
[其中  是与 μ 最远可接受的点。]
是与 μ 最远可接受的点。]
从数据手册公式

我们知道

而 invNorm(0.99) [不是 0.98!] 是 2.326




因此,需要抽取 112 个样本才能 98% 确定样本均值与总体均值之间的差异小于 0.3(n 向上取整至 112)。
请注意,对于**比例**, 可能并不总是已知的。在这种情况下,应该使用最大的可能误差,即
可能并不总是已知的。在这种情况下,应该使用最大的可能误差,即

如上所述,这等于最大可接受范围,例如 0.03,如果比例必须“在 3% 以内”。
假设检验的目的是在特定显著性水平下考虑假设的有效性,并得出关于其准确性的结论。想法是
显著性水平很像显著性检验的置信水平。例如,90% 的置信区间包含 90% 的分布,而 10% 的显著性水平意味着假设为真或假的可能性为 90%(10% 的误差几率)。
在任何假设检验中,都会有两个相互排斥的假设
 ,零假设,它陈述的是*相等*。在被证明为假之前,它被认为是正确的。
,零假设,它陈述的是*相等*。在被证明为假之前,它被认为是正确的。 ,备择假设,如果 被随机样本数据证明为假,就会被采用。
,备择假设,如果 被随机样本数据证明为假,就会被采用。
例如,检验每小时电话呼叫次数的平均值是否大于 6


备择假设可以是单边的,如上所示,也可以是双边的。如果我们想证明电话呼叫的平均数量**不等于** 6,我们会说  . 这意味着要么
. 这意味着要么  **或**
**或**  . 这在概率计算方式上略有不同(参见置信区间中的 invNorm() 参数),但很大程度上由计算器处理。
. 这在概率计算方式上略有不同(参见置信区间中的 invNorm() 参数),但很大程度上由计算器处理。
要进行检验,必须收集数据,从而获得 的值。然后,根据总体 σ 是否已知,计算z 或 t 分数( 或
或  ),使用以下公式:
),使用以下公式:
 或
或 (记住要说明
(记住要说明  自由度)。
自由度)。
使用比例时


所有 CLT 要求都需要满足各自的方法: 用于样本均值和  或
或  用于比例。
用于比例。
下一步是确定 p值 ,即z或t分数出现的概率。对于z分数,可以使用normalcdf()函数进行计算,但对于t分数,整个过程必须在计算器上完成(下面会解释)。p值衡量的是 在平均值为μ,标准差为σ的情况下出现的可能性。如果p值较低,则样本错误(可增加样本量以验证此点)或平均值不为μ(拒绝零假设)的可能性很高。p值被认为“过低”的临界值由显著性水平决定:在0.05(5%)的显著性水平下,如果p值低于0.05,则 将被拒绝。
对于双尾检验 ( ),p值是概率
),p值是概率 ,而对于单尾检验 (
,而对于单尾检验 ( 或
或  ),它只是
),它只是 或
或  和 方面的等价物。
和 方面的等价物。
假设检验步骤
- 陈述 , 以及检验是单尾还是双尾。
- 陈述是z分布还是t分布,计算相应的检验统计量 或 。
- 陈述决策规则(如果p值...则拒绝)。计算检验统计量的p值。
- 做出决策:“拒绝”或“接受”。
- 简要陈述将决策置于背景中。
“简要”陈述将尽可能多地包含来自的信息。例如,“基于对200块饼干的样本,在1%的显著性水平下,没有足够的证据来接受超过60%的饼干含有巧克力的假设”。
还有一种稍微不同的方法来判断计算的z得分是否可接受。而不是将z得分转换为概率,然后与p值进行比较,而是根据显著性水平计算临界值z得分。然后使用逻辑判断计算的z得分是否落在拒绝域内。例如,在 5% 的显著性水平下进行检验时,一个“<”单尾检验 可以被拒绝,如果 < invNorm(0.05)。对于一个“>”单尾检验,如果 > invNorm(0.95) 则拒绝,对于一个双尾检验,如果  invNorm(0.975) 则拒绝。
invNorm(0.975) 则拒绝。
计算器(TI)
计算器函数非常容易使用。一般来说
 和
和  共同构成备择假设。例如,如果
共同构成备择假设。例如,如果  那么
那么  且
且  。同样适用于 “
。同样适用于 “ ” 和
” 和  在 1-PropZTest 中。
在 1-PropZTest 中。 是成功的次数
是成功的次数 是试验次数
是试验次数- 是样本均值
 是总体标准差 (z 检验) 和 是 ,总体方差的无偏估计。
是总体标准差 (z 检验) 和 是 ,总体方差的无偏估计。
弄清楚哪些变量是已知的,将有助于在不确定如何开始的情况下找到正确的函数。
- 错误地拒绝 是一个I 类错误。发生这种情况的可能性等于执行检验的显著性水平。
- 错误地接受 是一个 **第二类错误**。 随着显著性水平的严格程度提高,临界区域缩小,犯第二类错误的可能性会增加。 计算犯第二类错误的概率需要一个备择值,即“真实”均值。第二类错误是指在均值实际上为b时,接受均值为a的可能性,这意味着犯第二类错误的概率取决于b。 因此,第二类错误是指在真实均值为b时,获得样本均值 的可能性 - 这可以通过使用 normalpdf 计算得出。
该分布可用于通过比较预期值与观察数据来检验数据集是否遵循特定分布。 它还可以用于假设两个变量是否相互依赖。
卡方 (χ2) 分布取决于自由度。 自由度越高,它越接近正态曲线。
请注意,所有 χ2 检验都是单尾检验。 所以不要把p值除以 2 或任何其他奇怪的操作。
对于 GOF 检验, 说明数据遵循一个分布,而 说明数据不遵循该分布。 例如
- : 数据来自均匀分布
- : 数据不是来自均匀分布。
自由度ν = 类别数 (n) - 限制数 (k)。 当没有明显的限制(大多数情况)时,k = 1,这是因为类别数是有限的。 一旦除一个之外的所有值的找到,最后一个类别就无法波动。 这意味着一般来说,对于 GOF 检验,ν = n - 1。
要计算数据集遵循特定分布的概率,请将观察值和预期值分别输入到不同的列表中。 如果任何预期频率低于 5,则将该组与相邻组合并。 这样做是为了避免在计算检验统计量时除以较小的数字,这会导致过大的值。 由于在执行此操作时类别数会减少,因此相应地减少自由度。 此外,对于每个统计量 ( ) 从 ν 中减去 1,这些统计量用于计算预期数据,但本身又是基于观察数据得出的。
) 从 ν 中减去 1,这些统计量用于计算预期数据,但本身又是基于观察数据得出的。
然后使用这些数据执行 χ2GOF 检验。 与假设检验一样,p值显示获得大于使用此数据集获得的 χ2 分数的可能性,因此,如果它小于置信度水平 应该被拒绝,可以得出结论,数据在该特定水平下不遵循该分布。
在检验变量的独立性时,使用双变量列联表。 这列出了两个变量的频率组合。 例如
将吸烟与高血压相关的列联表
|
|
吸烟量 |
| 高血压程度 |
无
|
中等
|
重度
|
总计
|
| 严重
|
10
|
14
|
20
|
44
|
| 轻度
|
20
|
18
|
31
|
69
|
| 无
|
40
|
22
|
25
|
87
|
| 总计
|
70
|
54
|
76
|
200
|
在将数据输入计算器时,将省略“总计”列和行。 预期值不必手动计算(这可以通过将行总计乘以列总计,然后除以“总计总计”来完成,例如 70×44/200 = 15.4,预期值表中的第一个单元格)。 相反,执行 χ2 检验,预期值将被插入到“预期”矩阵中。
χ2 检验中的自由度为(行数-1)(列数-1)。
当存在 2×2 列联表时,ν = 1。 通常情况下,会使用 Yates 的连续性校正,但是这已经从教学大纲中删除了。 因此,只需照常进行,ν = 1 即可。
对于独立性检验
- : 变量相互独立。
- : 变量相互依赖。
与往常一样,p值是观察到的 χ2 值大于观察到的 χ2 值的概率。 因此,如果显著性水平低于p值,则拒绝。

