
Conlang/高级/语法/支配
此材料存在一些重大问题;请参阅 讨论页面. |
句法是句子的结构如何以及为何这样:句子元素之间的关系以及这些关系编码的内容。它是一种语言将意义片段组织成对世界、想法、情景等的表示的方式。没有句法,就无法将任何特定的意义放入声音或符号中,也无法从声音或符号中获取任何特定的意义。简而言之,没有句法,就没有语言,就像没有有意义的成分,就没有语言一样。
词序影响语法的一些例子
- 1) 狗咬了人。
- 2) 狗是棕色的。
- 3) *人咬了狗。
- 4) *狗是棕色的。
词序影响意义的一些例子
- 5) 人咬了狗。
- 6) 狗咬了人。
- 7) 狗是棕色的吗?
[注意:句子前的星号表示语法错误。句子前的上标问号表示语法存疑或未知,或者只对某些说话者有效。]
句法一般描述两件事:某些东西可以放在哪里,以及这些位置意味着什么。在这个层面上,我们将观察各种语言,比较它们实现相同目标的不同方式。稍后,在高级句法教程中,我们将回过头来尝试找出是否可以使用相同的句法基本规则和结构来描述所有语言,以及为什么它们看起来如此不同。
与更简单的句法方法不同,本教程将深入探讨语言学理论。传统方法只是讨论像SOV vs. SVO vs. 等词序之类的事情,本教程将探讨产生这些词序的底层结构和规则。在高级句法教程中,我们将看到我们制定的规则如何更清楚地阐明这种情况,并促使我们抛弃SOV vs. SVO vs. 等词序作为句法中基本概念的简单概念。
本教程将介绍句法中使用的一些初步概念,主要是句子的结构成分。正如我们将在教程结束时看到的那样,我们可以用这种方法解释语言的大量特征,但我们仍然遗漏了语言实际产生的内容中的很大一部分。高级句法教程将带我们进入新的领域,探索一些旨在解释更多语言的理论。本教程和高级句法教程都将遵循Andrew Carnie的《句法:生成性导论》(第二版)的总体结构,可以看作是针对构词者的该书摘要。如果您认真想从P&P的角度理解句法,强烈推荐这本书。
本节的组成部分是
- 词性: 词汇属于哪些类别?
- 成分、树、规则: 词汇如何组合?
- 结构关系: 词汇和组合如何相互关联?
- 绑定理论: 为什么代词看起来行为很奇怪?
- 语言学普遍性: 各种语言的句法如何模式化?
- 应用知识: 如何在创造语言时应用这些知识?
- 找出问题: 该理论中还存在哪些问题?
众所周知,句子是由词汇构成的。但并非所有词汇都一样;一些词汇代表物体,一些词汇代表动作,等等。一个词汇代表什么——它的词性或句法类别——在它在语言句法中的行为中起着重要作用。我们可以识别出词汇的两大类。词汇词性本身就传达完整的意义,包括名词和动词等类别。另一方面,功能词性显示词汇之间的关系,或者为词汇提供额外的意义,包括介词和连接词等类别。
词汇词性可以分为四大类:名词(N)、动词(V)、形容词(Adj)和副词(Adv)。这些类别不一定是普遍存在的,它们彼此之间的区别在于它们的行为方式。将一个词汇识别为名词或动词是通过观察它做了什么来完成的:一个词汇是名词,因为它像名词一样表现,等等。这些特定类别是针对英语和许多印欧语系的,由于本教程是英文的,并且主要关注英语句法,因此将使用这些类别。
在非正式的或小学英语语法中,描述名词的典型方法是“人、地点或事物”。名词也可以是情绪、颜色、抽象概念,等等。名词通常可以有数量、特指性、形容词显示的属性、动作中的角色,等等。
动词通常表示动作,涉及某种变化,或表示存在状态,涉及一种存在方式与另一种存在方式的比较。它们通常可以描述为具有时态(发生时间)、体(通过时间发生的事件)、由副词表示的方式、由名词和其他短语表示的参与者等。
形容词
[edit | edit source]形容词描述名词的属性。它们可以表示颜色、形状,或更抽象的属性,如真实、诚实或荒谬。形容词本身可以具有品质或方式,由副词描述。
副词
[edit | edit source]副词描述非名词的属性,即动词、形容词和其他副词。它们可能是词汇类别中最抽象的。例如,“快速”是一个描述动词速度的副词,但在动作中没有可以测量的快速性,它是一个与红色这样的属性相比非常抽象和相对的概念。像“非常”这样的副词更加抽象。
功能性
[edit | edit source]功能类别比最抽象的副词更难概念化。它们传达了动词的时态、能力、许可和体,短语之间的关系,名词的特指性等。英语中一些常见的功能类别是介词(P)、限定词(D)、连接词(Conj)、补语引导词(C)、时态(T)和否定(Neg)。
特征
[edit | edit source]特征是抽象的语义属性,可以用来描述单词。一些属性,如复数性,没有其他属性那么抽象,如模态。它们倾向于成为有关单词的额外信息,与句子的结构相关,支配着单词与周围其他单词之间的关系。特征通常写在方括号内。具有特征用在特征前添加“+”表示,缺少特征用在特征前添加“–”表示。多个特征用逗号分隔。
一些特征示例
- [+plural]
- [–definite]
- [+past,+inchoative]
- [+Q,–WH]
在高级教程中,我们将看到特征本身如何用词汇表示,以及特征如何存在于某些地方并影响句子中单词的行为以传达某些含义。
在研究各种类型的词的行为时,我们发现它们最终被分成各种类别,这些类别支配着它们在句子中的放置方式。在某些语言中,这些子类别可以在词上显式标记(例如,西班牙语有显式标记的性别子类别,这支配着动词的语态一致),而在另一些语言中,子类别是隐式的,并且没有显示其所属子类别的任何标记。
在英语中,名词可以分为两类,可数名词,表示单个可数的项目,和不可数名词,表示不可数的事物或物质。可数名词需要数量指示,而不可数名词不需要。
- *Dog bit the man.
- A dog bit the man.
- The dog bit the man.
- Dogs bit the man.
可数名词只能与某些量词一起使用,而不可数名词则与另一些量词一起使用
- many cats
- *much cats
- much water
- *many water
如果我们想用子类别标记这些名词,可以用特征来标记。例如,可数名词和不可数名词之间的区别可以用特征 [±count] 来标记。
- dog[+count]
- cat[+count]
- water[-count]
动词子类别
[edit | edit source]我们还可以看一下英语中动词的一些子类别。通过检查动词接受的参数数量,以及它们在句子中的位置,我们可以发现动词的一些有用属性。
仅仅通过查看动词接受的参数数量(其价态),我们就能在英语中找到三种动词。不及物动词只接受一个参数,即主语,及物动词接受两个参数,即主语和直接宾语,双及物动词接受三个参数,即主语、直接宾语和间接宾语。一些动词似乎具有可选的及物性,例如动词“drive”:你可以说“I drive.”,但你也可以说“I drive a car.”。在这种情况下,我们可以说实际上有两个具有不同价态的动词。
动词也可能在句子中相对于它们的位置要求某些特定的东西。不及物动词要求它们的参数在它们之前。我们可以用一个特征来表示这一点,例如 [NP __],下划线表示动词的位置,NP 表示Noun Phrase。及物动词要求它们的 参数在它们之前和之后,这可以用特征 [NP __ NP] 或 [NP __ {NP/CP}](CP 表示Complement Phrase)表示。花括号包含可选的选项,用斜杠分隔。我们说一些及物动词的宾语可以是 NP 或 CP,因为我们有以下例子:“I said nothing.”,以及“I said that the pie was tasty.”。双及物动词可以用另一个特征来描述。
下面是英语动词子类别的示例表格,以及它们的匹配特征和示例
| 子类别 | 示例 |
|---|---|
| 不及物动词:V[NP __] | Leave |
| 及物动词类型 1:V[NP __ NP] | Hit |
| 及物动词类型 2:V[NP __ {NP/CP}] | Ask |
| 双及物动词类型 1:V[NP __ NP NP] | Spare |
| 双及物动词类型 2:V[NP __ NP PP] | Put |
| 双及物动词类型 3:V[NP __ NP {NP/CP}] | Give |
| 双及物动词类型 4:V[NP __ NP {NP/PP/CP}] | Tell |
成分、树形图、规则
[edit | edit source]成分是句子中任何相互关联形成一个单元的项目组。到目前为止,我们看到的唯一成分是单词,但还有其他类型的成分,即短语。短语是彼此之间联系更紧密的单词或短语组,而不是与组外单词和短语联系更紧密。通常我们说每个短语都有一个核心(一个词),每个核心都会生成一个短语,但并非总是如此。特定句法类别的核心会生成该类别的短语:名词(N)会生成名词短语(NP),动词(V)会生成动词短语(VP)等。我们也可以说短语可以由两个相同类型的连接短语组成,而没有核心。
我们可以通过询问两个词是否比其他词更紧密地相互关联来查看句子中的成分。例如,在“the dog bit the man”中,我们会说“the”和“dog”彼此构成一个成分,“the”和“man”构成一个成分,依此类推。知道形成了哪种短语取决于什么对成分的含义更重要。“The dog”和“the man”更多地是关于“dog”和“man”,而不太是关于“the”,因此这两个成分都将是 NP。
显示句子的成分层次结构
[edit | edit source]方括号
[edit | edit source]显示成分有两种方法。第一种方法是使用方括号。这在文本中是最容易做到的,因为它不需要任何特殊的形状或其他东西。显示成分的通用方法是在成分周围加上方括号,并在第一个方括号之后加上成分类型的下标。前一个示例句子中识别的两个成分将是
- 1) [NP [D the] [N dog]]
- 2) [NP [D the] [N man]]
有时你会看到一些成分被不完全地括起来,例如
- 3) [NP the dog]
- 4) [NP the man]
当被忽略的结构与显示成分所展示的内容无关时,就会发生这种情况。你可能还会看到没有标签的括号(例如 [the dog] 表示 [NP the dog]),当标签与上下文无关或可以从上下文中恢复时。当你从成分开始时,最好完全指示成分,无论其相关性如何。
树形图更常用于显示句子的结构。在树形图中,成分由节点和连接线表示。连接线将一个成分连接到另一个包含它的成分。节点本身代表类型(N、NP、V、VP 等)。词头(N、V 等)通常在它们下面写下实际的词。[NP [D the] [N dog]] 和 [NP [D the] [N man]] 的树形版本如下所示。
- 5 & 6)


 三角形用于表示成分未完全显示。
- 7 & 8)
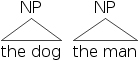

 绘制树形结构的一个普遍规则是连接线永不交叉。换句话说,一个成分必须由相邻的项目组成。在高级语法教程中,我们将探索如何处理非相邻成分及其出现的原因。
通过括号和树形图显示成分有助于描述特定句子的结构,但语法是关于描述所有句子的结构以及这些句子遵循的规则。因此,我们需要一种方法来描述哪些成分是可接受的,以及它们包含的内容。观察简单的例子“the dog”和“the man”,我们可以推导出英语 NP 的一些基本规则。在每个例子中,我们都有一个限定词后跟一个名词。如果我们将它们颠倒过来,得到“dog the”和“man the”,就会得到不语法短语,所以我们可以说 NP 由 D 后跟 N 组成。我们可以更简洁地表示为
- 9) NP → D N
当然,英语也允许在名词之前、限定词之后出现形容词短语 AdjP,例如“the big dog”(但不能像“big the dog”或“the dog big”那样),以及在名词之后出现介词短语 PP,例如“the dog in the house”(但不能像“in the house the dog”或“the in the house dog”那样)。因此,英语 NP 可以更完整地描述如下
- 10) NP → D AdjP N PP
我们可以使用 X、Y、Z 等作为元变量,表示任意词头类型。如果某项是可选的,我们将其放在括号内,例如 (XP)。交替选择放在花括号内并用斜杠分隔,例如 {XP/YP}。如果您需要任何数量的某项,例如“XP 或 XP XP 或 XP XP XP 或...” ,您可以将其中一项加上一个“+”,例如 XP+。这些可以组合起来创建多个可选项目——(XP+) 表示没有 XP、一个 XP、两个 XP 等——或多个项目的实例——{XP/YP/ZP}+ 表示一个或多个短语,每个短语可以是 XP、YP 或 ZP——等等。
这些规则,左侧是短语,右侧是该短语的内容,称为短语结构规则或 PS 规则。对于英语,我们可以用以下 PS 规则集来描述大量的句子
- 11) CP → (C) TP
- 12) TP → {NP/CP} (T) VP
- 13) VP → (AdvP+) V (NP) ({NP/CP}) (AdvP+) (PP+) (AdvP+)
- 14) NP → (D) (AdjP+) N (PP+) (CP)
- 15) PP → P (NP)
- 16) AdjP → (AdvP) Adj
- 17) AdvP → (AdvP) Adv
- 18) XP → XP conj XP
- 19) X → X conj X
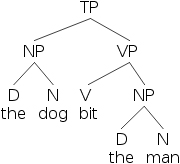
因此,如果我们想描述句子“the dog bit the man”,我们可以用这个带括号的句子
- 20) [TP [NP [D the] [N dog]] [VP [V bit] [NP [D the] [N man]]]]
以及树形图
- 21)


要为一种语言制定 PS 规则列表,有必要确定哪些形式构成成分。在某种程度上,我们可以通过直觉来判断母语的成分,但在很多情况下,很难判断什么是成分,什么不是成分。为了更容易确定成分,有许多测试可以在任何潜在的成分上执行。在高级语法教程中,我们将看到这些测试如何让我们有理由修改 PS 规则,并将它们重新表述为一个全新的理论。
测试成分的一种方法是看潜在的成分是否可以被单个词替换,而不影响句子的含义。
- 22a) The dog bit the man.
- 22b) The dog bit him.
- 23a) The dog bit the man.
- 23b) It bit him.
在这些例子中,我们看到代词替换了 D N 形式的词串,这表明 D N 形成一个成分。这当然是一个英语 NP。然后我们可以说,任何可以被代词替换的东西都是相同类型的成分,这让我们可以取任何句子集合,并识别代词可替换成分的例子,从而识别可以进入这些成分的东西。这就是我们获得构成 NP 规则的原因。
另一种成分测试是独立存在测试(也称为句子片段测试)。例如,如果一组词可以用作问题的答案,也就是说,如果它可以作为有意义的独立子句独立存在,那么我们可以说它是一个成分。
- 24a) The dog bit the man.
- 24b) The dog bit the man.
- What did the dog do?
- 25a) Bit the man.
- 25b) *Bit the.
这些表明“bit the man”形成了一些成分,而“bit the”在英语中不形成成分。* 通过继续对 V 的测试,我们找到了 VP 的定义。
* 在“the”和“him/her”形式相同的语言中,情况就不那么清楚了。例如,西班牙语的la "her"类似于la "the (feminine singular)"。
移动测试通过移动潜在的成分而不使句子变得不语法来显示成分。分裂式句子涉及在潜在成分之前插入 It is 或 It was,并在之后插入 that (26)。前置/伪分裂式句子涉及插入 Is/are what/who 以及潜在成分 (27)。将句子变成被动语态,交换主语和宾语,在前主语之前插入 by,并将动词变成被动语态(bit 变成 was bitten 等),也将表明成分。
- 26) It was the dog that bit the man.
- 27) The dog is what bit the man.
- 28) The man was bitten by the dog.
最后一种成分测试涉及取一个潜在的成分,并将其与另一个类似的东西连接起来。
- 29) The dog bit the man.
- 30) The dog and the cat bit the man.
成分测试并不总是保证。在某些情况下,一种语言似乎存在违反其他先前确定的成分的成分。
- 31) The cat saw and the dog bit the man.
(31) 会告诉我们“the cat saw”和“the dog bit”分别形成一个成分,因为它们似乎满足连接测试,这违反了先前确定的成分规则。这种情况需要进一步调查。解决这个问题的一种方法是在原则和参数框架中假设“the cat saw and the dog bit”实际上并不是成分,而是存在一个未说出口的代词(即,它具有词汇内容,但没有语音内容),称为 pro,它指的是“the man”。这将使我们能够将 (31) 重新分析为两个完整句子的连接。
- 32) [The cat saw [pro]i] and [the dog bit [the man]i]
这里下标“i”用于表示 pro 和 the man 引用的是同一个东西。在这个分析中,我们之前为英语找到的 PS 规则没有被违反。其他框架将以不同的方式处理这种情况。例如,词汇功能语法不使用 pro,而是允许更宽松的成分种类。这种测试失败表明句子中存在比表面上看起来更多的东西,我们在高级教程中将探索解决这些明显奇异的不同方法。
如前所述,树形结构具有不同的组成部分,即节点,它们包含或被其他节点包含。这种包含和共包含的层次结构使我们能够识别节点之间的一些关系,这些关系在描述语言中事物为什么表现为特定行为方面很有用。
从一些简单的 PS 规则开始
- 1) A → B C
- 2) B → D E
- 3) C → F G
- 4) F → H
我们可以生成一棵树
- 5)


 现在我们可以探索树形图的不同部分。A、B、... 是节点的示例。节点通过连接线连接在一起,这些连接线区分出不同的分支。B 及其下面的节点构成一个分支,与 C 及其下面的节点不同。D 是一个与 E 不同的分支,等等。如果一个节点下面只有一个分支,则称为非分支节点;如果它下面有多个分支,则称为分支节点。
- 6)

- 7)
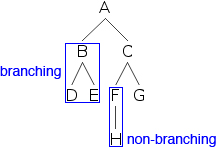


 在树的顶端,我们找到了 A,它不在任何其他节点的下方。这样的节点称为根节点。在底部,我们找到了 D、E、H 和 G,它们下方没有节点。这样的节点称为终端节点(有时也称为叶节点)。节点 A、B、C 和 F 都有节点在它们下方,被称为非终端节点。赋予节点的实际字母称为标签。
终端节点几乎总是词头(在高级语法教程中,我们将说所有终端节点也都是词头),所有非终端节点都是短语。
节点之间最简单的结构关系是支配关系。如果一个节点在树中位于另一个节点的上方,则该节点支配另一个节点。在示例树中,A 支配所有其他节点,B 支配 D 和 E,C 支配 F、H 和 G,F 支配 H。
- 8) 当且仅当 X 在树中比 Y 高(即 X 和根节点之间有更少的节点)并且您可以通过仅从 Y 向上到 X 或仅从 X 向下到 Y 来跟踪 X 和 Y 之间的路径时,节点 X 支配另一个节点 Y。
我们还可以说明哪些终端节点集合被哪些其他节点支配。例如,集合 {D, E} 被 B 和 A 都支配。对于 B,该集合与被 B 支配的节点集合相同,但对于 A,该集合仅是部分被 A 支配的节点。然后我们可以说 B 完全支配该集合,而 A 则不完全支配该集合。
- 9) 当且仅当 X 支配集合中的所有成员,并且所有被 X 支配的终端节点都是集合的成员时,节点 X 完全支配终端节点集合 {Y, ..., Z}。
- 10)


 我们还可以注意到节点在支配关系中彼此之间的距离关系。一些节点,例如 F,直接位于其他节点的上方,在本例中为 H,而其他支配节点,例如 A,则没有直接位于上方。当一个节点直接位于另一个节点的上方时,它直接支配该节点。
- 11) 当且仅当 X 支配 Z 并且没有节点 Y 支配 Z 并且本身被 X 支配时,节点 X 直接支配节点 Z。
- 12)


直接支配另一个节点的节点被称为该另一个节点的母节点。被另一个节点直接支配的节点被称为该另一个节点的子节点。同一个节点的子节点被称为姐妹节点。
另一种可以用支配关系来描述的简单关系是成分性。
- 13) 当且仅当 Y 支配 X 时,节点 X 是节点 Y 的一个成分。
- 14)


优先关系不像支配关系那么简单,但仍然相当简单。如果一个节点出现在另一个节点之前,则该节点优先于另一个节点。但优先关系有两种截然不同的类型,其中一种类型依赖于另一种类型。
- 15) 当且仅当 X 和 Y 都被同一个节点直接支配,并且 X 出现在 Y 的左侧时,节点 X 姐妹优先于节点 Y。
- 16)



- 17) 当且仅当两个节点都不支配另一个节点,并且 X 或支配 X 的节点姐妹优先于 Y 或支配 Y 的节点时,节点 X 优先于节点 Y。
- 18)


优先关系的直接性在分析直接宾语和间接宾语等方面可以发挥重要作用。优先关系中的直接性与支配关系中的直接性类似,因此定义将类似。
- 19) 当且仅当 X 优先于 Z 并且没有节点 Y 优先于 Z 并且本身被 X 优先时,节点 X 直接优先于节点 Z。
- 20)


C-支配可能是构建语言语法工作理论时最实用的结构关系。如果您理解支配和姐妹关系,那么 C-支配关系应该很容易理解。基本上,如果一个节点是另一个节点的姐妹节点,或者是一个支配该节点的节点的姐妹节点,则该节点 C-支配另一个节点。
- 21) 当且仅当直接支配 X 的节点也支配 Y 时,节点 X C-支配节点 Y。
您可以通过遵循一个简单的规则来找到被 C-支配的节点:向上走一步,然后向下走一步或多步,您所到达的任何节点都将被您开始的节点 C-支配。
- 22)


C-支配关系也可能表现出对称性。对称性在某些成分的行为中可以发挥重要作用。对称 C-支配本质上是姐妹关系。不对称 C-支配本质上是所有其他 C-支配情况。
- 23) 当且仅当 X C-支配 Y 并且 Y C-支配 X 时,节点 X 对称 C-支配节点 Y。
- 24) 当且仅当 X C-支配 Y 并且 Y 不 C-支配 X 时,节点 X 不对称 C-支配节点 Y。
- 25)



支配是另一种重要的关系。它建立在 C-支配之上,因此很容易用 C-支配来定义。它看起来非常类似于直接性关系。
- 26) 当且仅当 X C-支配 Z 并且没有节点 Y C-支配 Z 并且本身被 X C-支配时,节点 X 支配节点 Z。
- 27)


有些支配关系只适用于词头之间或短语之间。我们可以根据参与节点的类型定义支配关系的两种子类型。
- 28) 当且仅当 X C-支配 Z,没有节点 Y C-支配 Z 并且本身被 X C-支配,并且 X、Y 和 Z 都是词头/终端节点时,节点 X 词头支配节点 Z。
- 29) 当且仅当 Z C-支配 X,没有节点 Y C-支配 Z 并且本身被 X C-支配,并且 X、Y 和 Z 都是短语/非终端节点时,节点 X 短语支配节点 Z。
- 30)

- 31)

最后一种关系是语法关系。这些根本不是结构关系,而是语义关系,这些关系往往在语言中以相同的结构形式结束。在高级语法教程中,其中一些将被修改。
这些关系完全取决于语言的 PS 规则,在本例中为英语。
- 32) 主语 (S):TP 的 NP 或 CP 子节点。
- 33) (直接)宾语 (O 或 DO):由及物动词引导的 VP 的 NP 或 CP 子节点。
- 34) 介词宾语:PP 的 NP 或 CP 子节点。
- 35)


 英语有一种类型的宾语,称为间接宾语 (IO)。间接宾语有时可以像普通的宾语一样出现,有时可以像介词宾语一样出现。
- 36)

- 37)



 现在,我们有了两种类型的宾语,它们都可能成为 VP 的 NP 子节点,我们需要重新定义“直接宾语”一词,并定义“间接宾语”。
- 38) 直接宾语 (v2)
- a) VP 的 NP 或 CP 子节点,带有 V[NP __ NP]、V[NP __ CP]、V[NP __ {NP/CP}] 和 V[NP __ NP PP]
- b) VP 的 NP 或 CP 子节点,被 NP 或 PP 姐妹优先,带有 V[NP __ {NP/PP} {NP/CP}]
- 39) 间接宾语
- a) VP 的 PP 子节点,紧接在 VP 的 NP 子节点之前,带有 V[NP __ NP PP]
- b) VP 的 NP 子节点,紧接在 V 之前,带有 V[NP __ NP {NP/CP}]
还有一种类型的宾语,斜宾语,通常用介词标记,如
- 40) 我吃 [PP 带果酱] 的吐司。
斜宾语可以出现在与间接宾语相同的位置,有时也可以出现在直接宾语的位置。斜宾语与其他类型宾语的区别在于它是否出现在动词的论元特征中。例如,动词“eat”具有论元特征 [NP __ NP]。如果一个 PP(例如“with jam”)出现在句子中,那么它一定是一个斜宾语,因为它没有在论元特征中指示。
绑定理论试图通过我们迄今为止建立的结构框架来解释涉及代词和反身代词的某些现象。要理解这个理论的由来,首先要理解这些词的特殊之处,以及它们如何区别于普通名词。
普通名词被称为R-表达式(“r”代表“引用”)。它们的意义源于它们对句子之外的事物的引用,即世界上的事物(例如,“树”,“汽车”)。另一方面,代词的意义源于对句子中其他词的引用(对R-表达式),或者来自语境等(例如,“他”,“她”,“他们”)。最后,反身代词的意义只能来自句子中的R-表达式(例如,“它自己”,“我们自己”)。
我们可以在这些语法错误的句子中找到代词和反身代词特殊行为的例子
- 1) *它自己咬了狗。
- 2) *他看到了约翰。(其中“他”指的是约翰)
所以问题是为什么这些句子语法错误,为了找出原因,我们需要确定在语法正确的例子和语法错误的例子之间有什么区别。
首先要介绍一种方法来指示两个短语是否指代世界上的同一实体。我们将通过在每个唯一实体的词或短语之后使用唯一的下标字母来实现这一点。
- 3) [狗]i 咬了 [人]j。
- 4) [鲍勃]i 给 [玛丽亚]j [书]k。
- 5) [约翰]i 认为 [他]j 喜欢 [苹果派]k。
- 6) [弗朗辛]i 在 [镜子]j 中看到了 [她自己]i。
这种索引允许我们通过识别每个短语上的相同下标来记录何时两个短语指代同一个实体。通过拥有相同的索引,也就是说,通过共指,我们可以确定它们共指同一个实体。
其次,需要一个简单的赋予意义的概念。如果一个短语赋予另一个短语意义,我们将称之为先行词。
现在我们可以探索一些语法正确和语法错误的句子,找出一些初始的相似点和差异。
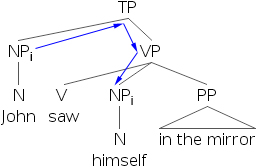
- 7) 约翰i 在镜子里看到了自己i。
- 8) [约翰i 的狗]j 在镜子里看到了自己j。
- 9) *[约翰i 的狗]j 在镜子里看到了自己i。
通过检查结构,我们发现反身代词自己不能与包含在另一个位于主语位置的短语中的R-表达式共指。如果我们检查下面的树形图,我们会发现,在语法正确的例子中,先行词总是c-支配反身代词。
- 10)
- 11)
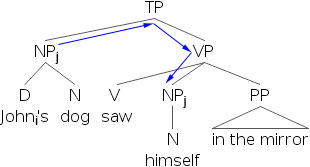
- 12)




 现在我们可以定义绑定
- 13) 当且仅当X c-支配Y,并且X和Y共指时,节点X绑定节点Y。
在7-9中,只有当反身代词被先行词绑定时,句子才是语法正确的。如果这是普遍的,那么我们应该找到反身代词绑定先行词的语法错误的情况。
- 14)


 由于这些都是语法错误,让我们用这条规则来解释。
- 15) 原则A:反身代词必须被其先行词绑定。
如果英语像那样简单,我们就完成了绑定的学习,但不幸的是,英语并没有那么简单。我们可以很容易地找到一些例子,其中反身代词被其先行词绑定,但句子仍然是语法错误的。
- 16)
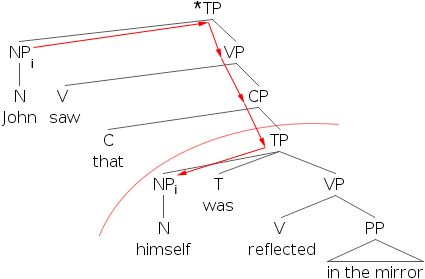

 为了解释这一点,我们必须引入绑定域的概念。简单来说,绑定域是包含反身代词的从句(TP)。现在,我们注意到(16)中,先行词位于反身代词绑定域之外。我们可以修改原则A,使其包含一个局部性约束(一条涉及接近度的规则)。
- 17) 原则A(v.2):反身代词必须在其绑定域内被其先行词绑定。
现在,这个理论就足够了,但在高级语法教程中,我们将研究一些在绑定域内但仍然是语法错误的容易找到的绑定例子,并且我们将看到如何修改我们的理论使其更适合。
代词的行为恰好与反身代词相反。考虑以下句子
- 18) 约翰i 在镜子里看到了他j。
- 19) *约翰i 在镜子里看到了他i。
- 20) 约翰i 看到他i 反映在镜子里。
- 21) 约翰i 看到他j 反映在镜子里。
- 22)
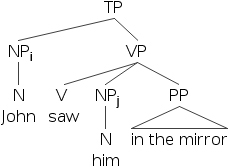
- 23)

- 24)

- 25)





 在(18)中,代词是未绑定的(或自由的),但在(19)中,代词是绑定的。观察嵌入从句,我们发现,如果代词位于嵌入从句中,即不同的绑定域,那么无论共指与否,句子都是语法正确的。在语法正确的例子中,代词在其绑定域内是自由的,而在语法错误的例子中,它是绑定的。我们可以从这一点中得出第二条规则。
- 26) 原则B:代词必须在其绑定域内是自由的。
在反身代词和代词之后,最后要处理的是R-表达式,即所有不是反身代词和代词的名词和短语。起初,鉴于我们之前的规则,我们似乎不需要描述它们可以放置的位置,但是我们可以找到完全是语法错误的句子,它们并没有违反原则A或B。
- 27) *他i 咬了费多i。
- 28) *鲍勃i 看到了弗兰克i。
- 29) 他i 咬了费多j。
- 30) 鲍勃i 看到了弗兰克j。
- 31)
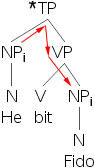
- 32)

- 33)

- 34)





 在这些情况下,我们注意到,只有当R-表达式被绑定时,句子才是语法错误的。现在,我们可以得出第三条规则。
- 35) 原则C:R-表达式必须是自由的。
有了绑定,我们现在拥有一个相当完整的工具来描述语言的许多行为,包括结构方面的行为,并且我们可以开始研究使用这些知识可以做些什么。
现代语言学最关心的问题之一是发现所有人类语言的根本原则。正如我们在高级语法教程中将看到的那样,这将是进一步发展我们已经讨论的理论的动力。但即使在我们目前工作的水平上,我们也可以探索自然语言中的一些趋势,这些趋势让我们洞悉了从认知过程如何形成句子到语法特征如何随时间发展等问题。
这些趋势被称为语言普遍性或语法普遍性,它们分为两种类型:纯粹的统计趋势,以及真正的普遍性(或“蕴含普遍性”)。统计趋势就是统计趋势——在模式中出现的趋势,很可能是在受认知便利性等多种力量影响下,通过历史变化而产生的。另一方面,蕴含普遍性往往得到更加严格的遵循,并做出预测性陈述,即如果一种语言具有特征X,那么它几乎肯定会也具有特征Y。还有其他方法来划分普遍性,例如,它们影响的语言部分。语音/音韵普遍性涉及语言所经历的声音和声音变化,形态普遍性涉及词语结构和语素,等等。在本节中,我将介绍与语法相关的普遍性,并探讨这些普遍性可能如何从语法中产生。
词序类型学是根据语言中某些类型的词语在句子或成分中相对于彼此的顺序来对语言进行分类。最常见的词序类型学分类是句子中主语、宾语和动词的顺序。由于有三种类型的词语,因此我们有六种可能的配置:VSO、SVO、SOV、VOS、OVS、OSV。在对自然语言的调查中,前三种(主语位于宾语之前)绝大多数被用作正常的陈述句词序,后三种占较低的个位数百分比。我们将这两种词序分别称为 SO 和 OS。对于每种词序,我们还将根据动词的位置来标识它们,分别用 I、II 和 III 表示动词位于句首、句中和句尾。然后可以通过两种组合来对语言进行分类,例如 SO/I、OS/III 等。由于 SO 词序非常普遍,因此 SO 词序可以简单地根据动词位置数字来推断(例如 III 表示 SO/III 而不是 OS/III 等)。
对语言进行分类的第二种方法是根据其使用介词或后置词,我们分别称之为 Pr 和 Po。第三种是形容词和名词的顺序;如果名词在其形容词之前,我们可以称之为 N,如果名词在其形容词之后,我们可以称之为 A。查看 Pr/Po 和 A/N 分类与 I/II/III 分类之间的关系,我们可以发现一些有趣的趋势,例如 I 型语言总是也是 Pr,III 型语言通常是 Po 等等。现在我们可以列出可能的配置(忽略罕见的 OS 配置)并查看它们的频率。
- I-PR-A:罕见
- I-PR-N:常见
- I-PO-A:罕见
- I-PO-N:罕见
- II-PR-A:常见
- II-PR-N:更常见
- II-PO-A:罕见
- II-PO-N:不太罕见
- III-PR-A:罕见
- III-PR-N:罕见
- III-PO-A:更常见
- III-PO-N:常见
仅从这些数据和我们之前对语法的了解,我们发现了一个趋势,这对构建可信的语言很有帮助。常见的形式 I-PR-N、II-PR 和 III-PO 与其他形式或子形式相比,都显示出对保持一致的头部位置的偏好,即语言更倾向于尽可能地保持头部位于句首或句尾。
句法普遍性比典型的词序普遍性更具体。它们仍然在句子的词序中可见,但它们的范围往往更专业。例如,在是非问句中,疑问词倾向于出现在它们所标记的词语之后,并且它们倾向于更多地出现在 II 型和 III 型语言中;当它们出现在 I 型语言中时,疑问词出现在它们所标记的词语之前。助动词也表现出有趣的句法模式,这种模式遵循关于一致头部位置的概括。
形态句法普遍性介于句法普遍性和形态普遍性之间,因为它们涉及与句法特征相关的形态学趋势。例如,我们发现形态学项目倾向于表现得与 PP 中的头部相似,即如果一种语言只有后缀,那么它应该表现得像使用后置词的语言,并且是 III 型,实际上也确实如此。实际上,如果一种语言只有后缀,那么它就有后置词,如果它只有前缀,那么它就有介词。
在名词和形容词一致的情况下,N 语言总是具有一致的形容词。更一般地,III 型语言几乎总是具有格系统。与语言之间语法相关趋势的全部复杂性超出了本节的范围,但您可以在此处阅读更多相关信息。我们可以从这些普遍性中推导出的一些含义将构成一套很好的语法规则。例如,词缀表现得像介词的趋势可能表明一些隐藏的结构,这些结构将词缀作为一些介词状短语的头部,经历了从介词到词缀的历史变化,从而使我们了解了如何使构造语言演变。语言试图在头部位置上保持一致的趋势可能是由于一个历史过程,该过程将词类相互转变。或者,为了使语言真正具有外星感,可以颠倒这些普遍性,从而使 Po 成为 I 型语言或类似的东西。了解普遍性显然可以更容易地创造出自然主义语言和有趣的外星语言。
格林伯格,约瑟夫。“语法的一些普遍性”。1999 年。2007 年 12 月 10 日 <https://web.archive.org/web/20100531044540/http://angli02.kgw.tu-berlin.de/Korean/Artikel02/>。
到目前为止,我们已经探索了语法作为一组形式理论的开端,但本教程旨在帮助构建语言。为了了解如何使用这些知识,我将从两个角度来探讨构建语言的过程。第一个是从头开始构建,没有任何关于语言语法应该是什么样的先入为主的想法。然后,我将探讨如何将一些模糊的想法扩展成完整的语言,并期待这些系统出现在其中,在此过程中,我将探讨如何使用相同的工具来规范现有语言。
从头开始设计语法在理论上是一个简单的过程。在没有任何关于某些特征应该是什么样的先入为主的想法的情况下,我们可以遵循一个有序的方法来进行这个过程。实际上,这个过程是如此公式化,以至于即使是列出要为语言定义的事项列表也可能有用。
- 1:头部位于句首还是句尾
- 2:头部和短语(即,语言有 Ns 吗?NPs 吗?Vs 吗?VPs 吗?等等)
- 3:与 (1) 不同的短语或具有例外替代形式的短语
- 4:PS 规则
在 (2) 和 (4) 中要牢记的是,结构不必与英语完全相同。现代理论倾向于尝试用相同的基本公式来描述每种语言,相同之处越多越好,但这并不意味着您的语言必须如此。如果您想将主语放到 VP 中,并将宾语从 VP 中移出,当然可以这样做。但请记住,制定截然不同的规则意味着您的成分测试应该具有等效的形式。如果您确实将主语移入 VP,并将宾语移出,那么您将需要一种情况,您可以在其中用一个替代词(类似于“do so”)替换 VP,并且具有相同含义。重要的是要牢记我们为什么说语言具有我们为它们发现的规则,或者如前所述,是我们开发的规则。
为预先存在的思想寻找语法比从头开始设计语法要复杂一些。因为我们已经有一些“规范”形式,所以我们必须对它们进行测试以发现它们的行为方式。也许我们可以列出一些要在这里做的事情来识别语言的特征。
- 1:成分测试以确定构成结构的内容及其方式
- 2:PS 规则以描述结构
- 3:结构的头部位置是典型的还是例外?
- 4a:1-3 的概括作为从头开始设计语法的步骤指南
- 4b:创建更多想法并对其进行分析
拥有多个想法可以更容易地决定 (3)。例如,如果我们有三个想法最终具有相同的头部位置,那么我们可能想说我们的语言应该具有该位置作为典型位置。或者,如果这些想法具有不同的头部位置,我们可以选择我们更喜欢的那个并将其设为典型,而将另一个设为例外。
上面列出的规则同样适用于描述过程,将整个语言视为一个需要分析的巨大想法。来自非正式语法的输入可以加快创建正式语法的过程。
当前理论非常强大,可以解释自然语言中的许多现象。尽管如此,它仍然错过了大量至少在英语中是语法的句子,并且所给出的理论根本无法解释某些语言。
我们目前的理论是以英语为基础的,但英语本身存在一些明显的反例。仅在名词短语内部,我们就发现了低于 NP 但高于 N 的成分结构示例。例如,“the big brown dog and the little one too”。在这个例子中,“one” 替换了 “brown dog”,表明 “brown dog” 本身就是一个成分,但根据我们现有的英语 PS 规则,这种情况是不可能出现的。因此,我们遇到了一个异常成分。
- [NP [D the] [AdjP big] [?? [AdjP brown] [N dog]]].
爱尔兰语
[edit | edit source]爱尔兰语属于 SO-I 语言类型,这意味着它采用 VSO 词序。使用上述语法,将主语作为 TP 的子节点会导致它无法出现在动词和宾语之间。如果我们在 V 和 VP 之间创建新的结构,就像我们对英语提出的建议那样,我们仍然会发现一些不符合词序的例句。例如,爱尔兰语在使用助动词时采用 AuxSVO 词序,这使得很难用一个规则来解释词序。
日语和拉丁语
[edit | edit source]日语和拉丁语有时被称为非配置语言,这意味着它们在句法层面上没有显著的词序。例如,日语只要求动词出现在句末(日语属于 III 类语言),以及动词补语出现在动词之前。拉丁语通常被认为是一个在句法层面上完全没有词序的语言。像这样的非配置语言需要大量的 PS 规则,每种可能的词序对应一条规则。对于长句来说,这很快就会变得难以驾驭。
在高级语法教程中,我们将了解现代语言学如何处理这些问题,并探索一些描述语言行为的实验方法,这些方法在虚构语言的构建过程中更有用。