
数据结构/堆栈和队列

堆栈是一种基本数据结构,可以从逻辑上将其视为线性结构,用实际物理堆栈或堆来表示,在这种结构中,项目的插入和删除发生在一个称为堆栈顶部的末端。基本概念可以通过将您的数据集想象为一叠盘子或书籍来说明,您只能取出堆栈顶部的项目才能从中移除东西。这种结构在整个编程中都被使用。
堆栈的基本实现也称为 LIFO(后进先出),以演示它访问数据的 方式,因为正如我们将看到的那样,堆栈实现有各种变化。
基本上可以在堆栈上执行三种操作。它们是 1)将项目插入堆栈(push)。 2)从堆栈中删除项目(pop)。 3)显示堆栈的内容(peek 或 top)。

下面是一些通常由堆栈数据类型支持的操作
Stack<item-type> 操作
push(new-item:item-type)- 将项目添加到堆栈。
top():item-type- 返回压入堆栈的最后一个项目。
pop()- 从堆栈中删除最近压入的项目。
is-empty():Boolean- 如果不再有项目可以弹出且没有顶部的项目,则为 true。
is-full():Boolean- 如果不再有项目可以压入,则为 true。
get-size():Integer- 返回堆栈上的元素数量。
除了get-size()以外的所有操作都可以在时间内执行。get-size()在最坏情况下运行时间为


基本的链表实现是您可以执行的最简单的堆栈实现之一。在结构上,它是一个链表。
type Stack<item_type>
data list:Singly Linked List<item_type>
"stack follows the LIFO (last in first out) operation"
"queue follows the FIFO (first in first out) operation"
constructor()
list := new Singly-Linked-List()
end constructor
大多数操作通过将它们传递到底层的链表来实现。当您想要将某些东西push到列表中时,您只需将其添加到链表的前面。然后,先前的顶部是“next”从正在添加的项目,并且列表的前面指针指向新的项目。
method push(new_item:item_type)
list.prepend(new_item)
end method
要查看top项目,您只需检查链表中的第一个项目。
method top():item_type
return list.get-begin().get-value()
end method
当您想要从列表中pop某些东西时,只需从链表中删除第一个项目。
method pop()
list.remove-first()
end method
检查是否为空很简单。只需检查列表是否为空。
method is-empty():Boolean
return list.is-empty()
end method
检查是否已满很简单。链表被认为是无限大小的。
method is-full():Boolean
return False
end method
检查大小再次传递到列表。
method get-size():Integer
return list.get-size()
end method
end type
发布库中的真实堆栈实现可能会重新实现链表,以便通过省略不必要的函数来从实现中挤出最后一部分性能。上面的实现为您提供了所涉及的思想,并且您可以通过内联链表代码来完成您需要的任何优化。
在链表中,访问第一个元素是一个操作。列表包含一个指针,用于检查空/满,就像这里完成的那样也是(取决于使用了什么时间/空间权衡)。大多数情况下,堆栈的用户不使用getSize()操作,因此可以通过不优化它来节省一些空间。
由于所有操作都在堆栈顶部,因此数组实现现在要好得多得多。
public class StackArray implements Stack
{
protected int top;
protected Object[] data;
...
}
数组实现将堆栈底部保留在数组的开头。它向数组的末尾增长。唯一的问题是,如果您尝试在数组已满时推入元素,那么
Assert.pre(!isFull(),"Stack is not full.");
将失败,并引发异常。因此,用 Vector(参见 StackVector)实现更有意义,以允许无界增长(以偶尔的 O(n) 延迟为代价)。
复杂度
所有操作都是 O(1),除了偶尔的 push 和 clear,它们应该用 null 替换所有条目,以便让它们被垃圾回收。数组实现不会替换 null 条目。Vector 实现会……

使用栈,我们可以解决许多应用,其中一些列在下面。
将十进制数转换为二进制数的逻辑如下
* Read a number
* Iteration (while number is greater than zero)
1. Find out the remainder after dividing the number by 2
2. Print the remainder
3. Divide the number by 2
* End the iteration
然而,这种逻辑存在问题。假设我们要找到的二进制形式的数字是 23。使用这种逻辑,我们得到的结果是 11101,而不是 10111。
为了解决这个问题,我们使用一个栈。我们利用栈的 *LIFO* 属性。最初,我们将形成的二进制数字 *push* 到栈中,而不是直接打印它。在整个数字都被转换为二进制形式之后,我们一次从栈中 *pop* 一个数字并打印它。因此,我们将十进制数转换为其正确的二进制形式。
算法
1. Create a stack
2. Enter a decimal number which has to be converted into its equivalent binary form.
3. iteration1 (while number > 0)
3.1 digit = number % 2
3.2 Push digit into the stack
3.3 If the stack is full
3.3.1 Print an error
3.3.2 Stop the algorithm
3.4 End the if condition
3.5 Divide the number by 2
4. End iteration1
5. iteration2 (while stack is not empty)
5.1 Pop digit from the stack
5.2 Print the digit
6. End iteration2
7. STOP

栈最有趣的应用之一是在解决一个叫做汉诺塔的谜题中。根据一个古老的婆罗门故事,宇宙的存在是根据一群僧侣所花费的时间来计算的,这些僧侣一直在工作,将 64 个圆盘从一根柱子移到另一根柱子上。但是,有一些关于如何做到这一点的规则,即
- 你一次只能移动一个圆盘。
- 为了临时存储,可以使用第三根柱子。
- 你不能把一个直径较大的圆盘放在一个直径较小的圆盘上。[1]
这里我们假设 A 是第一根柱子,B 是第二根柱子,C 是第三根柱子。





输出:(当有 3 个圆盘时)
假设 *1* 是最小的圆盘,*2* 是中等大小的圆盘,*3* 是最大的圆盘。
| 移动圆盘 | 从桩 | 到桩 |
|---|---|---|
| 1 | A | C |
| 2 | A | B |
| 1 | C | B |
| 3 | A | C |
| 1 | B | A |
| 2 | B | C |
| 1 | A | C |
输出:(当有 4 个圆盘时)
| 移动圆盘 | 从桩 | 到桩 |
|---|---|---|
| 1 | A | B |
| 2 | A | C |
| 1 | B | C |
| 3 | A | B |
| 1 | C | A |
| 2 | C | B |
| 1 | A | B |
| 4 | A | C |
| 1 | B | C |
| 2 | B | A |
| 1 | C | A |
| 3 | B | C |
| 1 | A | B |
| 2 | A | C |
| 1 | B | C |
这个解决方案的 C++ 代码可以用两种方法实现
这里我们假设 A 是第一根柱子,B 是第二根柱子,C 是第三根柱子。(B 是中间的)
void TowersofHanoi(int n, int a, int b, int c)
{
//Move top n disks from tower a to tower b, use tower c for intermediate storage.
if(n > 0)
{
TowersofHanoi(n-1, a, c, b); //recursion
cout << " Move top disk from tower " << a << " to tower " << b << endl ;
//Move n-1 disks from intermediate(b) to the source(a) back
TowersofHanoi(n-1, c, b, a); //recursion
}
}
// Global variable, tower [1:3] are three towers
arrayStack<int> tower[4];
void TowerofHanoi(int n)
{
// Preprocessor for moveAndShow.
for (int d = n; d > 0; d--) //initialize
tower[1].push(d); //add disk d to tower 1
moveAndShow(n, 1, 2, 3); /*move n disks from tower 1 to tower 3 using
tower 2 as intermediate tower*/
}
void moveAndShow(int n, int a, int b, int c)
{
// Move the top n disks from tower a to tower b showing states.
// Use tower c for intermediate storage.
if(n > 0)
{
moveAndShow(n-1, a, c, b); //recursion
int d = tower[a].top(); //move a disc from top of tower a to top of
tower[a].pop(); //tower b
tower[b].push(d);
showState(); //show state of 3 towers
moveAndShow(n-1, c, b, a); //recursion
}
}
然而,上面实现的复杂度是 O()。因此,很明显,这个问题只能解决 n 的较小值(通常 n <= 30)。在僧侣的情况下,按照上述规则将 64 个圆盘转移所需的转数为 18,446,744,073,709,551,615;这肯定需要很多时间!!

使用 逆波兰表示法 的计算器使用栈结构来保存值。表达式可以表示为前缀、后缀或中缀表示法。从一种形式的表达式转换为另一种形式可以使用栈来完成。许多编译器使用栈来解析表达式、程序块等的语法,然后再翻译成低级代码。大多数编程语言都是 上下文无关语言,使它们能够使用基于栈的机器进行解析。
输入 (((2 * 5) - (1 * 2)) / (9 - 7))
输出 4
分析:五种类型的输入字符
* Opening bracket * Numbers * Operators * Closing bracket * New line character
数据结构要求:一个字符栈
算法
1. Read one input character
2. Actions at end of each input
Opening brackets (2.1) Push into stack and then Go to step (1)
Number (2.2) Push into stack and then Go to step (1)
Operator (2.3) Push into stack and then Go to step (1)
Closing brackets (2.4) Pop it from character stack
(2.4.1) if it is opening bracket, then discard it, Go to step (1)
(2.4.2) Pop is used three times
The first popped element is assigned to op2
The second popped element is assigned to op
The third popped element is assigned to op1
Evaluate op1 op op2
Convert the result into character and
push into the stack
Go to step (2.4)
New line character (2.5) Pop from stack and print the answer
STOP
结果:完全括号的中缀表达式的求值将以如下方式打印在显示器上
输入字符串 (((2 * 5) - (1 * 2)) / (9 - 7))
| 输入符号 | 栈(从底部到顶部) | 操作 |
|---|---|---|
| ( | ( | |
| ( | ( ( | |
| ( | ( ( ( | |
| 2 | ( ( ( 2 | |
| * | ( ( ( 2 * | |
| 5 | ( ( ( 2 * 5 | |
| ) | ( ( 10 | 2 * 5 = 10 & *Push* |
| - | ( ( 10 - | |
| ( | ( ( 10 - ( | |
| 1 | ( ( 10 - ( 1 | |
| * | ( ( 10 - ( 1 * | |
| 2 | ( ( 10 - ( 1 * 2 | |
| ) | ( ( 10 - 2 | 1 * 2 = 2 & *Push* |
| ) | ( 8 | 10 - 2 = 8 & *Push* |
| / | ( 8 / | |
| ( | ( 8 / ( | |
| 9 | ( 8 / ( 9 | |
| - | ( 8 / ( 9 - | |
| 9 | ( 8 / ( 9 - 7 | |
| ) | ( 8 / 2 | 9 - 7 = 2 & *Push* |
| ) | 4 | 8 / 2 = 4 & *Push* |
| 换行 | 空 | *Pop* & 打印 |
C 程序
int main (int argc, char
struct ch *charactop;
struct integer *integertop;
char rd, op;
int i = 0, op1, op2;
charactop = cclearstack();
integertop = iclearstack();
while(1)
{
rd = argv[1][i++];
switch(rd)
{
case '+':
case '-':
case '/':
case '*':
case '(': charactop = cpush(charactop, rd);
break;
case ')': integertop = ipop (integertop, &op2);
integertop = ipop (integertop, &op1);
charactop = cpop (charactop, &op);
while(op != '(')
{
integertop = ipush (integertop, eval(op, op1, op2));
charactop = cpop (charactop, &op);
if (op != '(')
{
integertop = ipop(integertop, &op2);
integertop = ipop(integertop, &op1);
}
}
break;
case '\0': while (! cemptystack(charactop))
{
charactop = cpop(charactop, &op);
integertop = ipop(integertop, &op2);
integertop = ipop(integertop, &op1);
integertop = ipush(integertop, eval(op, op1, op2));
}
integertop = ipop(integertop, &op1);
printf("\n The final solution is: %d\n", op1);
return 0;
default: integertop = ipush(integertop, rd - '0');
}
}
}
int eval(char op, int op1, int op2)
{
switch (op)
{
case '+': return op1 + op2;
case '-': return op1 - op2;
case '/': return op1 / op2;
case '*': return op1 * op2;
}
}
程序的输出
在命令行输入的输入:(((2 * 5) - (1 * 2)) / (9 - 7)) [3]
输入 (2 * 5 - 1 * 2) / (11 - 9)
输出 4
分析:有五种类型的输入字符,即
* Opening brackets
* Numbers
* Operators
* Closing brackets
* New line character (\n)
如果将运算符作为输入字符读取,我们不知道该怎么办。通过实现运算符的优先级规则,我们找到了解决这个问题的方法。
如果读取运算符,则应执行比较优先级检查,然后将其压入。如果栈 *top* 包含的运算符的优先级高于或等于输入运算符的优先级,则我们将其 *pop* 并打印它。我们不断执行优先级检查,直到栈的 *top* 出现优先级较低的运算符或不包含运算符为止。
此问题的所需数据结构:一个字符栈和一个整数栈
算法
1. Read an input character
2. Actions that will be performed at the end of each input
Opening brackets (2.1) Push it into stack and then Go to step (1)
Digit (2.2) Push into stack, Go to step (1)
Operator (2.3) Do the comparative priority check
(2.3.1) if the character stack's top contains an operator with equal
or higher priority, then pop it into op
Pop a number from integer stack into op2
Pop another number from integer stack into op1
Calculate op1 op op2 and push the result into the integer
stack
Closing brackets (2.4) Pop from the character stack
(2.4.1) if it is an opening bracket, then discard it and Go to
step (1)
(2.4.2) To op, assign the popped element
Pop a number from integer stack and assign it op2
Pop another number from integer stack and assign it
to op1
Calculate op1 op op2 and push the result into the integer
stack
Convert into character and push into stack
Go to the step (2.4)
New line character (2.5) Print the result after popping from the stack
STOP
结果:未完全括号的中缀表达式的求值将按如下方式打印
输入字符串 (2 * 5 - 1 * 2) / (11 - 9)
| 输入符号 | 字符栈(从底部到顶部) | 整数栈(从底部到顶部) | 执行的操作 |
|---|---|---|---|
| ( | ( | ||
| 2 | ( | 2 | |
| * | ( * | *Push* 因为 * 的优先级更高 | |
| 5 | ( * | 2 5 | |
| - | ( * | 由于 - 的优先级较低,我们执行 2 * 5 = 10 | |
| ( - | 10 | 我们将 10 压入,然后压入 - | |
| 1 | ( - | 10 1 | |
| * | ( - * | 10 1 | Push * 因为它的优先级更高 |
| 2 | ( - * | 10 1 2 | |
| ) | ( - | 10 2 | 执行 1 * 2 = 2 并压入 |
| ( | 8 | Pop - 并且 10 - 2 = 8 并压入,Pop ( | |
| / | / | 8 | |
| ( | / ( | 8 | |
| 11 | / ( | 8 11 | |
| - | / ( - | 8 11 | |
| 9 | / ( - | 8 11 9 | |
| ) | / | 8 2 | 执行 11 - 9 = 2 并压入 |
| 换行 | 4 | 执行 8 / 2 = 4 并压入 | |
| 4 | 打印输出,即 4 |
C 程序
int main (int argc, char *argv[])
{
struct ch *charactop;
struct integer *integertop;
char rd, op;
int i = 0, op1, op2;
charactop = cclearstack();
integertop = iclearstack();
while(1)
{
rd = argv[1][i++];
switch(rd)
{
case '+':
case '-':
case '/':
case '*': while ((charactop->data != '(') && (!cemptystack(charactop)))
{
if(priority(rd) > (priority(charactop->data))
break;
else
{
charactop = cpop(charactop, &op);
integertop = ipop(integertop, &op2);
integertop = ipop(integertop, &op1);
integertop = ipush(integertop, eval(op, op1, op2);
}
}
charactop = cpush(charactop, rd);
break;
case '(': charactop = cpush(charactop, rd);
break;
case ')': integertop = ipop (integertop, &op2);
integertop = ipop (integertop, &op1);
charactop = cpop (charactop, &op);
while(op != '(')
{
integertop = ipush (integertop, eval(op, op1, op2);
charactop = cpop (charactop, &op);
if (op != '(')
{
integertop = ipop(integertop, &op2);
integertop = ipop(integertop, &op1);
}
}
break;
case '\0': while (!= cemptystack(charactop))
{
charactop = cpop(charactop, &op);
integertop = ipop(integertop, &op2);
integertop = ipop(integertop, &op1);
integertop = ipush(integertop, eval(op, op1, op2);
}
integertop = ipop(integertop, &op1);
printf("\n The final solution is: %d", op1);
return 0;
default: integertop = ipush(integertop, rd - '0');
}
}
}
int eval(char op, int op1, int op2)
{
switch (op)
{
case '+': return op1 + op2;
case '-': return op1 - op2;
case '/': return op1 / op2;
case '*': return op1 * op2;
}
}
int priority (char op)
{
switch(op)
{
case '^':
case '$': return 3;
case '*':
case '/': return 2;
case '+':
case '-': return 1;
}
}
程序的输出
在命令行输入的输入 (2 * 5 - 1 * 2) / (11 - 9)
输出: 4 [3]
输入: x + 6 * ( y + z ) ^ 3
输出:' 4
分析:有三种类型的输入字符
* Numbers
* Operators
* New line character (\n)
数据结构要求:一个字符栈和一个整数栈
算法
1. Read one character input at a time and keep pushing it into the character stack until the new
line character is reached
2. Perform pop from the character stack. If the stack is empty, go to step (3)
Number (2.1) Push in to the integer stack and then go to step (1)
Operator (2.2) Assign the operator to op
Pop a number from integer stack and assign it to op1
Pop another number from integer stack
and assign it to op2
Calculate op1 op op2 and push the output into the integer
stack. Go to step (2)
3. Pop the result from the integer stack and display the result
结果:前缀表达式的求值将按如下方式打印
输入字符串 / - * 2 5 * 1 2 - 11 9
| 输入符号 | 字符栈(从底部到顶部) | 整数栈(从底部到顶部) | 执行的操作 |
|---|---|---|---|
| / | / | ||
| - | / | ||
| * | / - * | ||
| 2 | / - * 2 | ||
| 5 | / - * 2 5 | ||
| * | / - * 2 5 * | ||
| 1 | / - * 2 5 * 1 | ||
| 2 | / - * 2 5 * 1 2 | ||
| - | / - * 2 5 * 1 2 - | ||
| 11 | / - * 2 5 * 1 2 - 11 | ||
| 9 | / - * 2 5 * 1 2 - 11 9 | ||
| \n | / - * 2 5 * 1 2 - 11 | 9 | |
| / - * 2 5 * 1 2 - | 9 11 | ||
| / - * 2 5 * 1 2 | 2 | 11 - 9 = 2 | |
| / - * 2 5 * 1 | 2 2 | ||
| / - * 2 5 * | 2 2 1 | ||
| / - * 2 5 | 2 2 | 1 * 2 = 2 | |
| / - * 2 | 2 2 5 | ||
| / - * | 2 2 5 2 | ||
| / - | 2 2 10 | 5 * 2 = 10 | |
| / | 2 8 | 10 - 2 = 8 | |
| 栈为空 | 4 | 8 / 2 = 4 | |
| 栈为空 | 打印 4 |
C 程序
int main (int argc, char *argv[])
{
struct ch *charactop = NULL;
struct integer *integertop = NULL;
char rd, op;
int i = 0, op1, op2;
charactop = cclearstack();
integertop = iclearstack();
rd = argv[1][i];
while(rd != '\0')
{
charactop = cpush(charactop, rd);
rd = argv[1][i++];
}
while(!emptystack(charactop))
{
charactop = cpop(charactop, rd);
switch(rd)
{
case '+':
case '-':
case '/':
case '*':
op = rd;
integertop = ipop(integertop, &op2);
integertop = ipop(integertop, &op1);
integertop = ipush(integertop, eval(op, op1, op2));
break;
default: integertop = ipush(integertop, rd - '0');
}
}
}
int eval(char op, int op1, int op2)
{
switch (op)
{
case '+': return op1 + op2;
case '-': return op1 - op2;
case '/': return op1 / op2;
case '*': return op1 * op2;
}
}
int priority (char op)
{
switch(op)
{
case '^':
case '$': return 3;
case '*':
case '/': return 2;
case '+':
case '-': return 1;
}
}
程序的输出
在命令行输入的输入:/ - * 2 5 * 1 2 - 11 9
输出:4 [3]
输入 (((8 + 1) - (7 - 4)) / (11 - 9))
输出 8 1 + 7 4 - - 11 9 - /
分析:有五种类型的输入字符,即
* Opening brackets
* Numbers
* Operators
* Closing brackets
* New line character (\n)
需求:一个字符栈
算法
1. Read an character input
2. Actions to be performed at end of each input
Opening brackets (2.1) Push into stack and then Go to step (1)
Number (2.2) Print and then Go to step (1)
Operator (2.3) Push into stack and then Go to step (1)
Closing brackets (2.4) Pop it from the stack
(2.4.1) If it is an operator, print it, Go to step (1)
(2.4.2) If the popped element is an opening bracket,
discard it and go to step (1)
New line character (2.5) STOP
因此,将中缀表达式转换为后缀表达式后的最终输出如下
| 输入 | 操作 | 栈(操作后) | 在显示器上输出 |
|---|---|---|---|
| ( | (2.1) 将操作数压入栈 | ( | |
| ( | (2.1) 将操作数压入栈 | ( ( | |
| ( | (2.1) 将操作数压入栈 | ( ( ( | |
| 8 | (2.2) 打印它 | 8 | |
| + | (2.3) 将运算符压入栈 | ( ( ( + | 8 |
| 1 | (2.2) 打印它 | 8 1 | |
| ) | (2.4) 从栈中弹出:由于弹出的元素是 +,因此打印它 | ( ( ( | 8 1 + |
| (2.4) 从栈中弹出:由于弹出的元素是 (,因此我们忽略它并读取下一个字符 | ( ( | 8 1 + | |
| - | (2.3) 将运算符压入栈 | ( ( - | |
| ( | (2.1) 将操作数压入栈 | ( ( - ( | |
| 7 | (2.2) 打印它 | 8 1 + 7 | |
| - | (2.3) 将运算符压入栈 | ( ( - ( - | |
| 4 | (2.2) 打印它 | 8 1 + 7 4 | |
| ) | (2.4) 从栈中弹出:由于弹出的元素是 -,因此打印它 | ( ( - ( | 8 1 + 7 4 - |
| (2.4) 从栈中弹出:由于弹出的元素是 (,因此我们忽略它并读取下一个字符 | ( ( - | ||
| ) | (2.4) 从栈中弹出:由于弹出的元素是 -,因此打印它 | ( ( | 8 1 + 7 4 - - |
| (2.4) 从栈中弹出:由于弹出的元素是 (,因此我们忽略它并读取下一个字符 | ( | ||
| / | (2.3) 将操作数压入栈 | ( / | |
| ( | (2.1) 压入栈 | ( / ( | |
| 11 | (2.2) 打印它 | 8 1 + 7 4 - - 11 | |
| - | (2.3) 将操作数压入栈 | ( / ( - | |
| 9 | (2.2) 打印它 | 8 1 + 7 4 - - 11 9 | |
| ) | (2.4) 从栈中弹出:由于弹出的元素是 -,因此打印它 | ( / ( | 8 1 + 7 4 - - 11 9 - |
| (2.4) 从栈中弹出:由于弹出的元素是 (,因此我们忽略它并读取下一个字符 | ( / | ||
| ) | (2.4) 从栈中弹出:由于弹出的元素是 /,因此打印它 | ( | 8 1 + 7 4 - - 11 9 - / |
| (2.4) 从栈中弹出:由于弹出的元素是 (,因此我们忽略它并读取下一个字符 | 栈为空 | ||
| 换行符 | (2.5) 停止 |
这是一个非常好的堆栈应用。假设一辆货运列车有 n 节车厢,每节车厢都要在不同的车站卸货。它们编号从 1 到 n,货运列车按顺序从 n 到 1 访问这些车站。显然,车厢按目的地进行标记。为了方便从列车中卸下车厢,我们必须将它们按编号升序重新排列(即从 1 到 n)。当车厢按此顺序排列时,它们可以在每个车站卸下。我们在一个有 输入轨道、输出轨道 和 k 个位于输入轨道和输出轨道之间的存放轨道的调车场重新排列车厢(即 存放轨道)。
为了重新排列车厢,我们从前到后检查输入轨道上的车厢。如果正在检查的车厢是输出排列中的下一个车厢,我们将其直接移动到 输出轨道。如果不是,我们将其移动到 存放轨道,并在需要将其放置到 输出轨道 时将其留在那里。存放轨道以 LIFO 的方式工作,因为车厢从顶部进入和离开这些轨道。在重新排列车厢时,只允许以下移动
- 车厢可以从输入轨道的最前部(即右端)移动到其中一个 存放轨道 的顶部或输出轨道的左端。
- 车厢可以从 存放轨道 的顶部移动到 输出轨道 的左端。
该图显示了一个有 k = 3 个存放轨道 H1、H2 和 H3,以及 n = 9 的调车场。货运列车的 n 节车厢从输入轨道开始,并以从右到左 1 到 n 的顺序结束于输出轨道。车厢最初以从后到前的顺序排列,依次是 5、8、1、7、4、2、9、6、3。之后,车厢会按照需要的顺序重新排列。

- 考虑图中的输入排列,这里我们注意到车厢 3 在最前面,所以它还不能输出,因为它要排在车厢 1 和 2 之前。所以车厢 3 被分离并移动到存放轨道 H1。
- 下一个车厢 6 不能输出,它被移动到存放轨道 H2。因为我们必须在车厢 6 之前输出车厢 3,如果我们将车厢 6 移动到存放轨道 H1,这是不可能的。
- 现在很明显,我们将车厢 9 移动到 H3。
对任何存放轨道上的车厢重新排列的要求是,车厢应该从上到下按升序排列。
- 所以现在将车厢 2 移动到存放轨道 H1,这样就满足了前面的说法。如果我们将车厢 2 移动到 H2 或 H3,那么我们将没有地方移动车厢 4、5、7 或 8。当新车厢 λ 被移动到其顶部具有最小标签 Ψ 的存放轨道时,λ < Ψ,对未来车厢放置的限制最少。我们可能将其称为分配规则,以决定特定车厢是否属于特定存放轨道。
- 当考虑车厢 4 时,有三个地方可以移动车厢:H1、H2 和 H3。这些轨道的顶部分别是 2、6 和 9。所以使用前面提到的分配规则,我们将车厢 4 移动到 H2。
- 车厢 7 被移动到 H3。
- 下一个车厢 1 具有最小标签,所以它被移动到输出轨道。
- 现在是输出车厢 2 和 3 的时候了,它们来自 H1(简而言之,所有来自 H1 的车厢都附加到输出轨道上的车厢 1)。
车厢 4 被移动到输出轨道。现在没有其他车厢可以移动到输出轨道。
- 下一个车厢,车厢 8,被移动到存放轨道 H1。
- 车厢 5 从输入轨道输出。车厢 6 从 H2 移动到输出轨道,车厢 7 从 H3 移动到输出轨道,车厢 8 从 H1 移动到输出轨道,车厢 9 从 H3 移动到输出轨道。
排序是指将一组元素按特定顺序排列。无论是升序还是降序,按基数还是字母顺序,或者其他变体。最终排序的可能性只会受源元素类型的限制。
快速排序是一种 分而治之 类型的算法。在这种方法中,要对一组数字进行排序,我们将它缩减为两个更小的集合,然后对这些更小的集合进行排序。
以下示例可以解释这一点
假设 A 是以下数字的列表

在缩减步骤中,我们找到一个数字的最终位置。在本例中,假设我们必须找到 48 的最终位置,它是列表中的第一个数字。
为此,我们采用以下方法。从最后一个数字开始,从右到左移动。将每个数字与 48 进行比较。如果数字小于 48,我们在该数字处停止并将其与 48 交换。
在本例中,该数字是 24。因此,我们将 24 和 48 交换。

48 右边的数字 96 和 72 大于 48。现在从 24 开始,以相反的方向扫描数字,即从左到右。将每个数字与 48 进行比较,直到找到大于 48 的数字。
在本例中,它是 60。因此我们将 48 和 60 交换。

注意 48 左边的数字 12、24 和 36 都小于 48。现在,从 60 开始,以从右到左的方向扫描数字。一旦找到较小的数字,就将其与 48 交换。
在本例中,它是 44。将其与 48 交换。最终结果是

现在,从 44 开始,从左到右扫描列表,直到找到大于 48 的数字。
这样的数字是 84。将其与 48 交换。最终结果是

现在,从 84 开始,从右到左遍历列表,直到到达小于 48 的数字。我们在到达 48 之前没有找到这样的数字。这意味着列表中的所有数字都已被扫描并与 48 进行比较。此外,我们注意到所有小于 48 的数字都在它左边,所有大于 48 的数字都在它右边。
最终分区如下
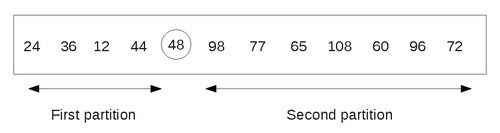
因此,48 已被放置到正确的位置,现在我们的任务简化为对两个分区进行排序。上述创建分区的步骤可以对包含 2 个或更多元素的每个分区重复。由于我们一次只能处理一个分区,因此我们应该能够跟踪其他分区,以备将来处理。
这是通过使用两个名为 LOWERBOUND 和 UPPERBOUND 的 堆栈 来完成的,以临时存储这些分区。分区的第一个和最后一个元素的地址分别被推入 LOWERBOUND 和 UPPERBOUND 堆栈。现在,只有在从堆栈中 弹出 其边界值后,才将上述缩减步骤应用于分区。
我们可以从以下示例中理解这一点
取上述包含 12 个元素的列表 A。该算法首先将 A 的边界值,即 1 和 12,分别推入 LOWERBOUND 和 UPPERBOUND 堆栈。因此堆栈如下所示
LOWERBOUND: 1 UPPERBOUND: 12
为了执行缩减步骤,堆栈顶部的值从堆栈中弹出。因此,两个堆栈都变为空。
LOWERBOUND: {empty} UPPERBOUND: {empty}
现在,缩减步骤导致 48 被固定在第 5 个位置并创建了两个分区,一个是从位置 1 到 4,另一个是从位置 6 到 12。因此,值 1 和 6 被推入 LOWERBOUND 堆栈,4 和 12 被推入 UPPERBOUND 堆栈。
LOWERBOUND: 1, 6 UPPERBOUND: 4, 12
为了再次应用缩减步骤,堆栈顶部的值被弹出。因此,值 6 和 12 被弹出。因此堆栈看起来像
LOWERBOUND: 1 UPPERBOUND: 4
现在将缩减步骤应用于第二个分区,即从第 6 个元素到第 12 个元素。

在缩减步骤之后,98 被固定在第 11 个位置。因此,第二个分区只有一个元素。因此,我们将第一个分区的上下边界值推入堆栈。因此,堆栈如下所示
LOWERBOUND: 1, 6 UPPERBOUND: 4, 10
处理以以下方式进行,并在堆栈不包含要处理的分区的任何上下边界以及列表已排序时结束。

在股票跨度问题中,我们将使用堆栈来解决一个金融问题。
假设对于一只股票,我们有一系列 n 天的每日价格报价,该股票在特定日期的价格 跨度 定义为股票价格在当前日期低于或等于该日期价格的连续天数的最大值。
输入:一个包含 n 个元素的数组 P
输出:一个包含n个元素的数组S,其中S[i]是满足以下条件的最大整数k:k <= i + 1 且 P[j] <= P[i](j = i - k + 1,.....,i)。
算法
1. Initialize an array P which contains the daily prices of the stocks
2. Initialize an array S which will store the span of the stock
3. for i = 0 to i = n - 1
3.1 Initialize k to zero
3.2 Done with a false condition
3.3 repeat
3.3.1 if (P[i - k] <= P[i]) then
Increment k by 1
3.3.2 else
Done with true condition
3.4 Till (k > i) or done with processing
Assign value of k to S[i] to get the span of the stock
4. Return array S
现在,分析该算法的运行时间,我们观察到
- 我们在开始时初始化了数组S,并在最后返回它。这是一个常数时间操作,因此需要O(n)时间。
- repeat循环嵌套在for循环内。for循环的计数器为i,执行n次。不在repeat循环内,但在for循环内的语句执行了n次。因此,这些语句以及i的递增和条件测试需要O(n)时间。
- 在外部for循环的i次重复中,内部repeat循环的主体最多执行i + 1次。在最坏情况下,元素S[i]大于所有之前的元素。因此,对if条件的测试,以及之后的语句,以及对until条件的测试,将在外部for循环的第i次迭代中执行i + 1次。因此,内部循环的总时间为O(n(n + 1)/2),即O()

所有这些步骤的运行时间通过将所有这三个步骤所花费的时间相加来计算。前两个项是O(),而最后一项是O()。因此,该算法的总运行时间为O()。

具有线性时间复杂度的算法
[edit | edit source]为了更有效地计算跨度,我们注意到,如果我们知道i之前最接近的那一天,使得该天的股票价格高于当前天的股票价格,则可以轻松地计算出特定一天的跨度。如果存在这样的日子,我们可以用h(i)表示它,并将h(i)初始化为-1。
因此,特定一天的跨度由公式s = i - h(i)给出。
为了实现这种逻辑,我们使用堆栈作为抽象数据类型来存储日期i、h(i)、h(h(i))等等。当我们从第i-1天到第i天时,我们会弹出股票价格低于或等于p(i)的日期,然后将第i天的值推回到堆栈中。
这里,我们假设堆栈由O(1)(即常数时间)的操作实现。该算法如下所示
输入:一个包含n个元素的数组P和一个空的堆栈N
输出:一个包含n个元素的数组S,其中S[i]是满足以下条件的最大整数k:k <= i + 1 且 P[j] <= P[i](j = i - k + 1,.....,i)。
算法
1. Initialize an array P which contains the daily prices of the stocks
2. Initialize an array S which will store the span of the stock
3. for i = 0 to i = n - 1
3.1 Initialize k to zero
3.2 Done with a false condition
3.3 while not (Stack N is empty or done with processing)
3.3.1 if ( P[i] >= P[N.top())] then
Pop a value from stack N
3.3.2 else
Done with true condition
3.4 if Stack N is empty
3.4.1 Initialize h to -1
3.5 else
3.5.1 Initialize stack top to h
3.5.2 Put the value of h - i in S[i]
3.5.3 Push the value of i in N
4. Return array S
现在,分析该算法的运行时间,我们观察到
- 我们在开始时初始化了数组S,并在最后返回它。这是一个常数时间操作,因此需要O(n)时间。
- while循环嵌套在for循环内。for循环的计数器为i,执行n次。不在repeat循环内,但在for循环内的语句执行了n次。因此,这些语句以及i的递增和条件测试需要O(n)时间。
- 现在,观察i次重复for循环时内部while循环的情况。done with a true condition语句最多执行一次,因为它会导致退出循环。假设t(i)是执行Pop a value from stack N语句的次数。因此,很明显,while not (Stack N is empty or done with processing)最多测试t(i) + 1次。
- 将while循环中所有操作的运行时间加起来,我们得到

- 从堆栈N中弹出的元素永远不会被推回堆栈中。因此,

因此,while循环中所有语句的运行时间为O()
算法中所有步骤的运行时间通过将所有这些步骤所花费的时间相加来计算。每个步骤的运行时间为O()。因此,该算法的运行时间复杂度为O()。
相关链接
[edit | edit source]队列
[edit | edit source]队列是一种基本的数据结构,在整个编程过程中都有使用。你可以把它想象成杂货店的队伍。排在队伍最前面的人是第一个被服务的人。就像队列一样。
队列也被称为FIFO(先进先出),以演示它访问数据的方式。
Queue<item-type>操作
enqueue(new-item:item-type)- 将一个项目添加到队列的末尾。
front():item-type- 返回队列最前面的项目。
dequeue()- 从队列的前面移除项目。
is-empty():Boolean- 如果不再有项目可以出队,并且没有前面的项目,则为真。
is-full():Boolean- 如果不再有项目可以入队,则为真。
get-size():Integer- 返回队列中的元素数量。
除了get-size()以外的所有操作都可以在时间内执行。get-size()在最坏情况下运行时间为
基本的链表实现使用一个单向链表,并带有一个尾指针来跟踪队列的尾部。
type Queue<item_type>
data list:Singly Linked List<item_type>
data tail:List Iterator<item_type>
constructor()
list := new Singly-Linked-List()
tail := list.get-begin() # null
end constructor
当你想入队某个元素时,你只需将它添加到尾指针指向的元素的后面。所以,之前尾部被认为是新添加元素的下一个元素,并且尾指针指向新元素。如果列表为空,这将不起作用,因为尾部迭代器不指向任何元素。
method enqueue(new_item:item_type)
if is-empty()
list.prepend(new_item)
tail := list.get-begin()
else
list.insert_after(new_item, tail)
tail.move-next()
end if
end method
队列上的头部元素就是链表头指针指向的那个元素。
method front():item_type
return list.get-begin().get-value()
end method
当你想出队列表中的某个元素时,只需将头指针指向头部的上一个元素。旧的头元素就是从列表中删除的元素。如果列表现在为空,我们必须修复尾部迭代器。
method dequeue()
list.remove-first()
if is-empty()
tail := list.get-begin()
end if
end method
检查是否为空很简单。只需检查列表是否为空。
method is-empty():Boolean
return list.is-empty()
end method
检查是否已满很简单。链表被认为是无限大小的。
method is-full():Boolean
return False
end method
检查大小再次传递到列表。
method get-size():Integer
return list.get-size()
end method
end type
在链表中,访问第一个元素是一个 操作,因为列表包含一个直接指向它的指针。因此,入队、头部和出队都是快速的 操作。
此处完成的空/满检查也是。
getSize()的性能取决于链表实现中对应操作的性能。它可能是,也可能是,这取决于所做的时间/空间权衡。大多数情况下,队列的用户不使用getSize()操作,因此可以通过不优化它来节省一些空间。

双端队列是一个同构元素列表,其中插入和删除操作在两个端点上执行。
由于这个属性,它被称为双端队列,即双端队列。
双端队列有两种类型
- 输入限制队列:它只允许在一个端点插入
- 输出限制队列:它只允许在一个端点删除